深入golnag
string
一个比特可以是0也可以是1,8个比特组成一个字节,可以是0~255,组合起来就可以表示更大的数字。
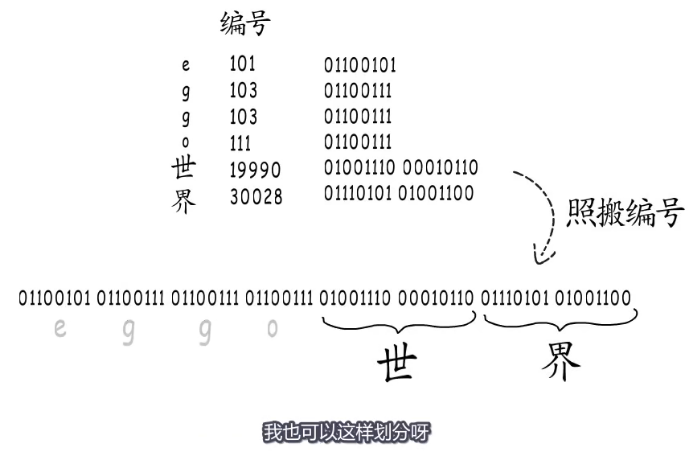
字符集用来表示字符,历史有ASCII(1967),GB2312(1980),BIG5(1984),
在表示存储字符的时候发生一个问题,就是表示的字符不能简单的拼接起来,计算机不知道如何划分边界,从而不知道需要表示的字符,如下图。
定长编码

变长编码
开头表示需要占用几个字节,比如1110开头需要占用三个字节,后面的10开头表示一个字节,后面紧跟的是编码内容。也就是utf-8的编码模式。

golang中的string。
在c语言中内容的末尾会有一个标识符,\0,但是也限制了内容中不可以出现这个标识符,所以go语言中没有采用这样的标识符。而是在起始位置的后面多存一个字节长度个数,所以能找到存储内容的开头和结尾。
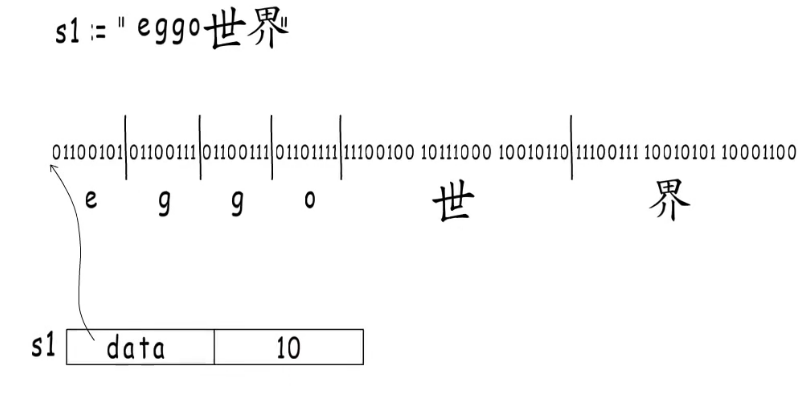
在go语言中可以读取字符串的内容,但是无法修改字符串的内容,这一点和python有很大的区别。
slice
slice有三个部分组成,
- 第一部分元素存哪里
- 第二部分存了多少个元素
- 第三部分可以存多少个元素
make声明
如果声明一个数组使用make
var ints []int = make([]int,2,5)
ints = append(ints,1)
ints[0] = 1
// 这里的ints中的data没有起始位置所以为nil
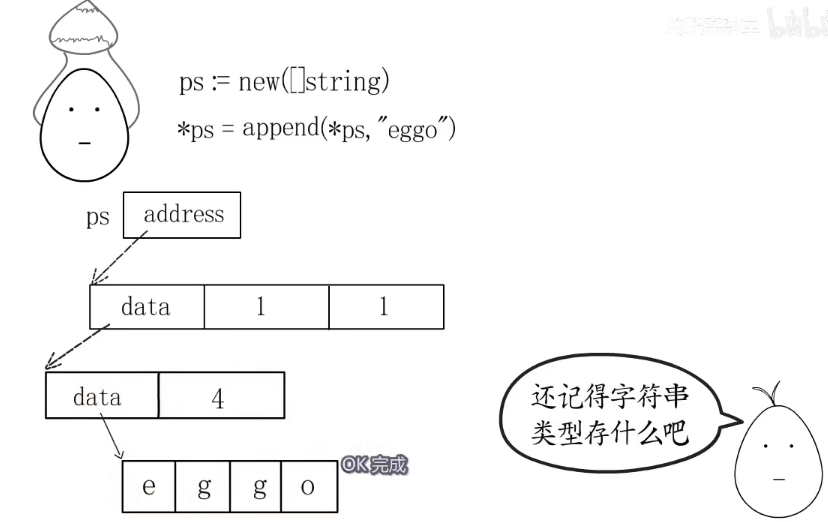
new声明
ps := new([]string)不负责底层数组的分配,这里的ps就是data的地址。
没有分配地址可以通过append函数添加元素分配地址。
数组
数组就是同种类型的元素一个挨一个的存储,int型的slice底层就是int数组,string型的slice 底层就是 string的数组。
arr := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} // 数组容量声明了就不能变了
var s1 []int = arr[1:4] // slice 可以共用同一个底层数组
var s2 []int = arr[7:]
fmt.Println(s1) //[1 2 3]
fmt.Println(s2) //[7 8 9]slice扩容规则
第一步,预告扩容后的容量newCap,
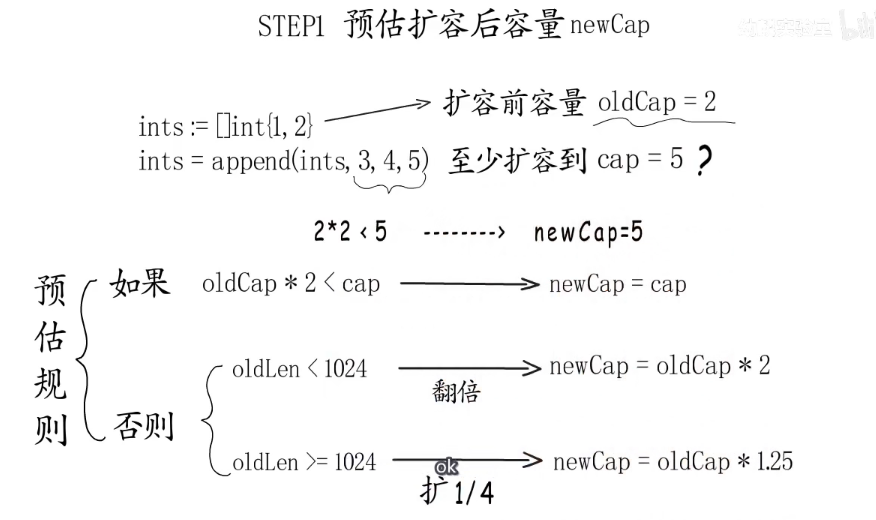
第二步,newCap个元素需要多大内存
在很多的编程语言中,申请分配内存并不是直接和操作系统交涉,而是和语言自身实现的内存管理模块,他会提前向操作系统申请一批内存,分成常用的规格管理起来。
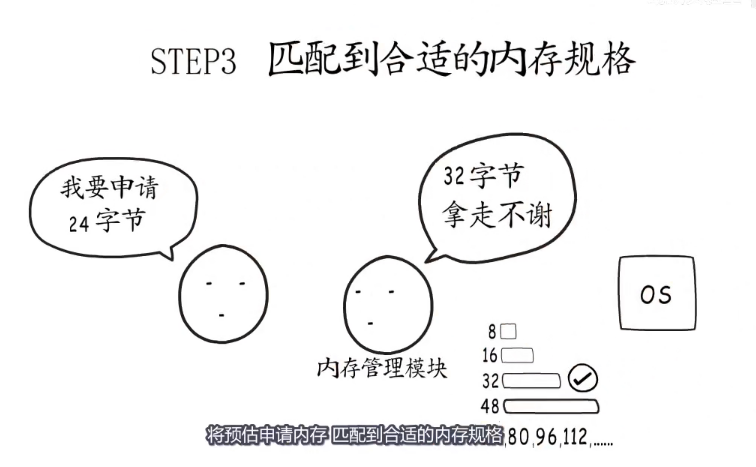
第三步,将预估申请的内存匹配到合适的内存规格
例子

第一步预估,添加一个元素至少需要到4,翻倍容量大于4,小于1024,所以预估容量为6。
第二步,预估容量乘以元素大小,为96字节、
第三步,匹配到的内存规格为96字节,所以最终扩容后容量为6
结构体和内存对齐
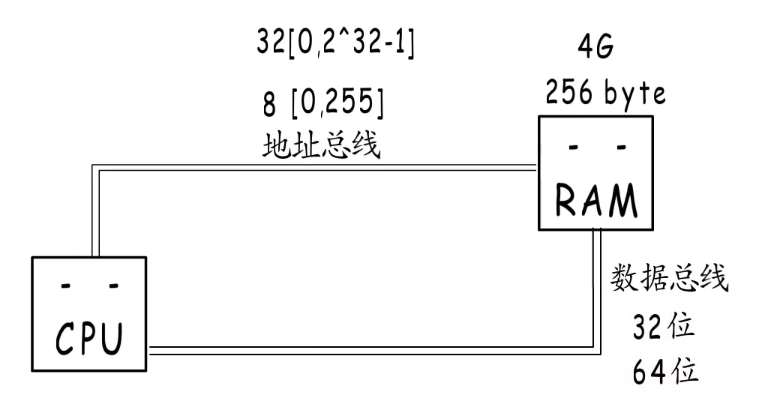
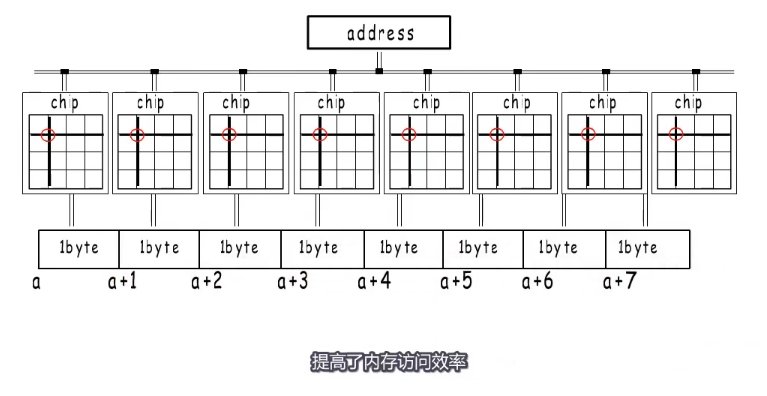
如果cpu需要读取内存数据,需要通过地址总线把地址传输给内存,内存准备好数据输出到数据总线交给cpu。
如果地址总线只有8根,那这个地址只能表示0~255的地址,所以256就是8根地址总线最大的寻址空间,如果要使用更大的内存就需要更宽的地址总线,例如32位的地址总线就可以寻址4G的内存。所以如果想每次操作4字节就需要32位的数据总线,如果是8字节就需要64位的地址总线。这里每次操作的字节数就是所谓的机器字长。
一个内存条一面是一个rank,一面有很多的颗粒为chip,一个颗粒里面有8个banks,在bank中就可以通过选择行列来定位地址。这样可以组成逻辑上的8个字节。
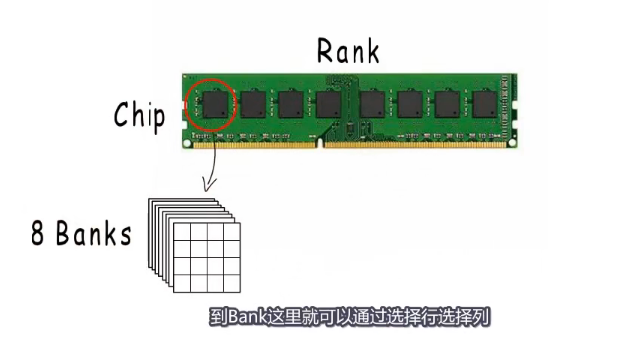
每个bank上表示的字节不同,组成我们逻辑上的8个字节。
为了保证程序的高效运行,编译器会把各种类型的数据安排到合适的地址,并占用合适的长度,也就是内存对齐,每种类型的对齐值就是它的对齐边界。内存对齐要求数据存储地址,以及占用的字节数都要是它对齐边界的倍数, 这里int32只能从4开始,不能从2开始。
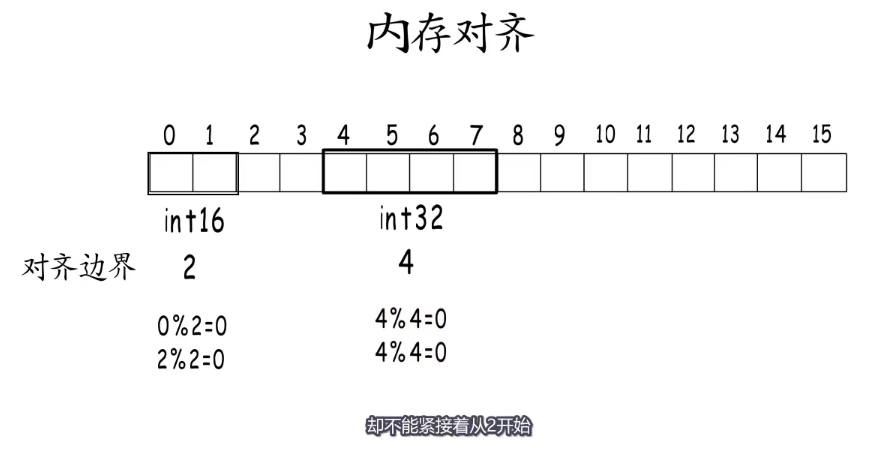
!!!未完全理解
map
map的常规理解
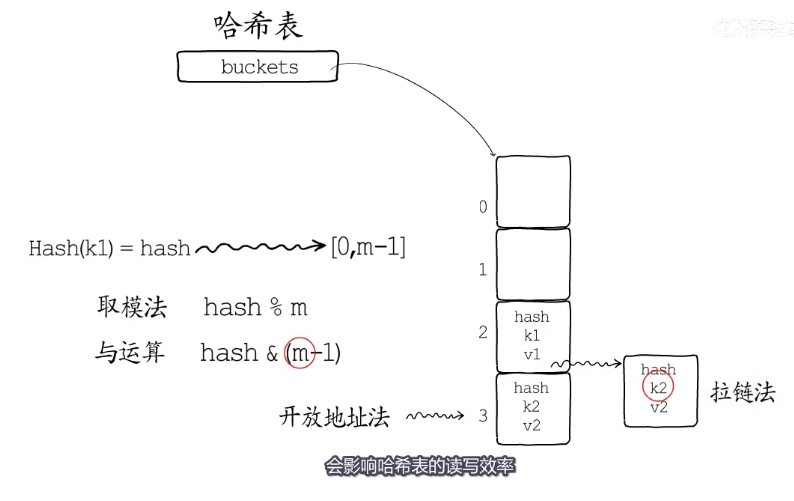
go语言中
map类型的变量本质上是一个指针指向hmap结构体
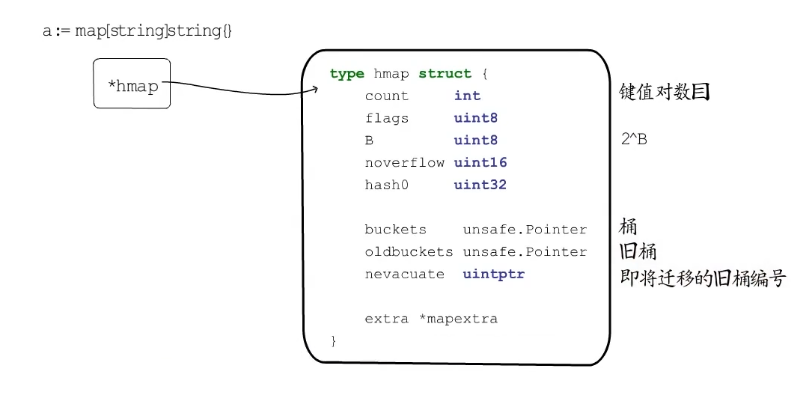
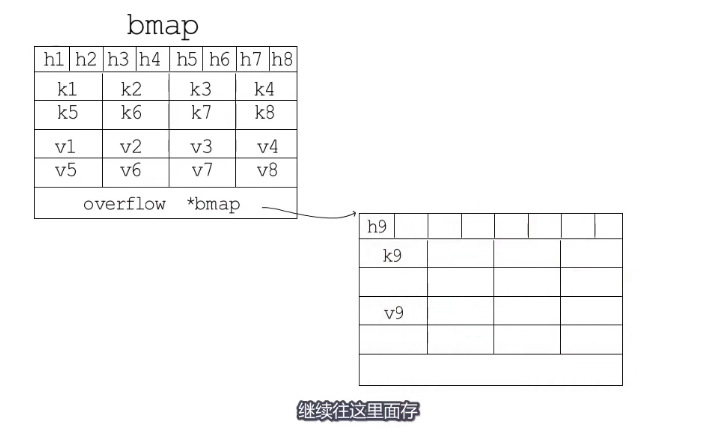
bmap的结构
一个桶里可以放8个键值对,为了让内存更加紧凑8个key放一起,8个value放一起,8个key的前面是8个tophash,每个tophash都是对应哈希值的高8位。最后是一个bmap类型的指针,指向一个溢出桶,溢出桶的内存布局和常规桶是相同的, 是为了减少扩容次数而引入的,如果一个通存满了,就会往溢出桶里面存。
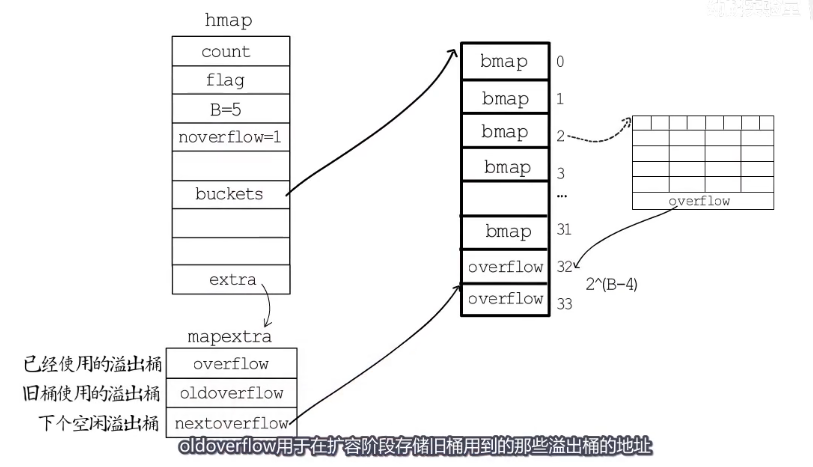
hmap结构体的最后有一个extra的字段,指向一个mapextra结构体,里面记录的都是溢出桶相关的信息。
nextoverflow指向下一个空闲溢出桶的位置overflow是一个slice记录已经使用的溢出桶的地址。noverflow记录溢出桶的数量。
例子:
没有太听懂
函数调用栈(一)
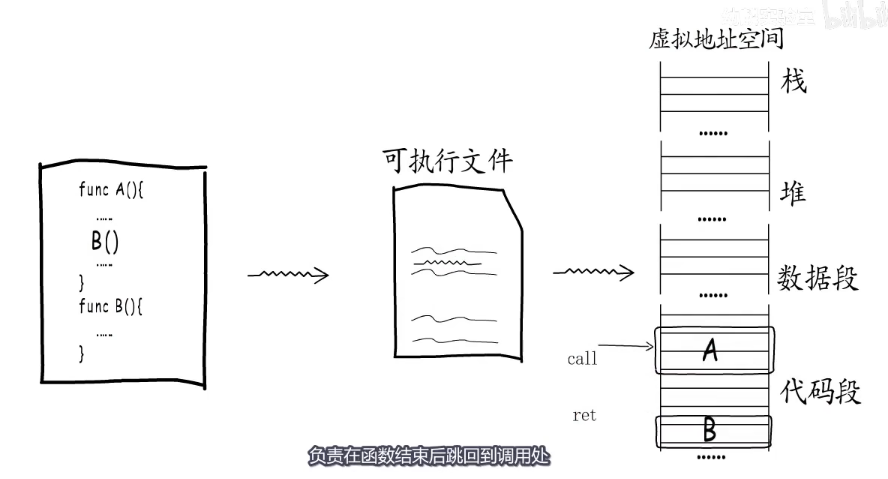
我们根据编程语法定义的函数,会被编译为一堆机器指令,写入到可执行文件,程序执行的时候可执行文件加载到内存中。
栈
这些机器指令对应到虚拟地址空间中,位于代码段,如果在函数中调用另一个函数,编译器就会对应生成一条call指令,程序执行到这条指令时,就会跳转到被调用函数入口处开始执行,而每个函数的最后都有一条ret指令,负责在函数结束后条回到调用处继续执行。
函数执行的时候需要有足够的内存空间,用于存放局部变量,参数等数据,这段空间对应到虚拟地址空间的栈。栈只有一个口进出,先入栈的在底,后入栈的在顶,是一个后进先出的原则。
运行时栈上面的时高地址,向下增长,分配给函数的栈空间被称为函数栈帧,栈底通常称为栈基,栈顶又称为栈指针。在go语言中函数栈帧布局中,先是调用者栈基地址,然后是局部变量,然后是调用函数的返回值,最后是参数。
call指令只做两件事,第一将下一条指令的地址入栈,这就是返回地址,被调用函数执行结束后会跳回到这里,第二,跳转到被调用函数入口处执行,这后面就是被调用函数的栈帧了,所有函数栈帧布局都遵循统一的约定。所以被调用者是通过栈指针加上相应的偏移来定位到每个参数和返回值的。
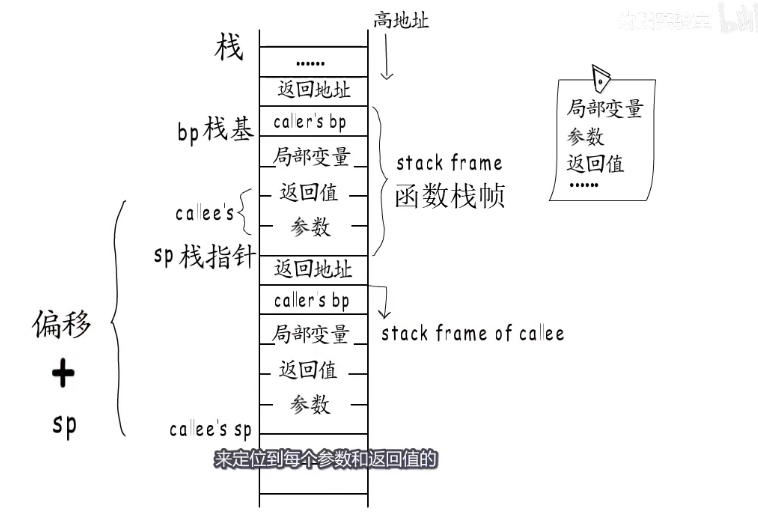
寄存器
程序执行的时候cpu用特殊的寄存器来存储运行时栈基和栈指针,同时也有指令指针寄存器用于存储下一条要执行的指令地址。
一般程序在编译的时候都会根据编写的代码把所有的程序按照代码编译进行入栈。但是在go语言中函数的栈帧不是这样逐步扩张的,而是一次性分配。
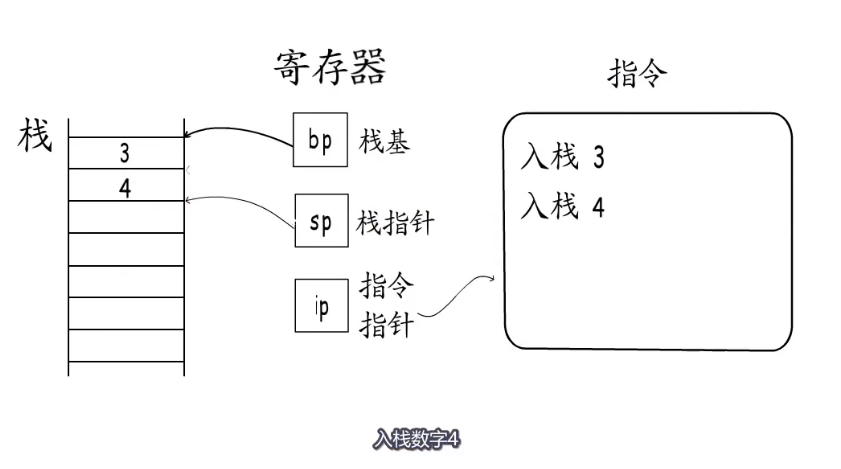
go语言的栈指针
go语言在分配栈指针的时候,直接将栈指针移动到所需最大栈空间的位置,然后通过栈指针加上偏移值这种相对寻址方式使用函数栈帧,例如这里sp+16字节处存储3,sp+8字节处存储4.
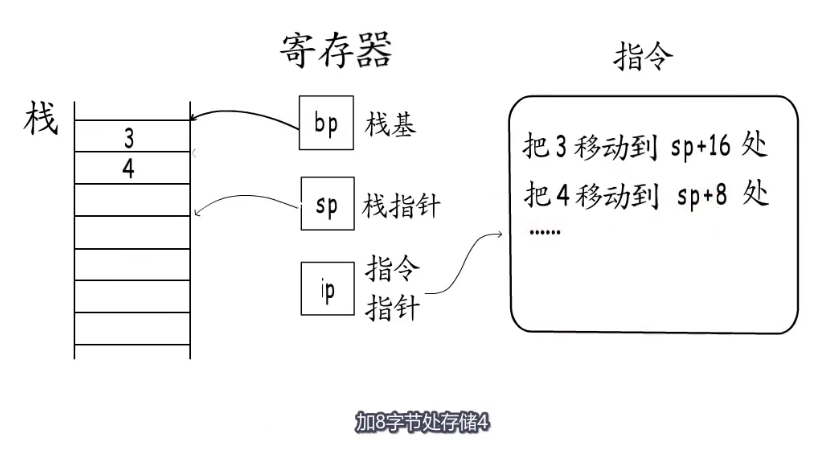
go栈空间
一次分配主要是为了避免栈访问越界,如果初始分配的栈空间就这么大,如果函数栈是逐步扩张的,执行期间就可能发生栈的访问越界。函数的栈帧的大小在编译的时候是可以确定的,所以go语言的编译器会在函数的头部插入检测代码,如果发现需要进行“栈增长”,就会另外分配一段足够大的栈空间,并把原来的数据拷过来,原来的栈空间就释放了。
go函数的call指令和ret指令
一个函数A在a1处调用b1处的函数B,在跳转前,到了call指令这里作用有两点,第一把返回地址a2入栈保存起来,第二跳转到指令地址b1处,call指令就结束了,函数B就开始执行,这里是一个相对寻址。
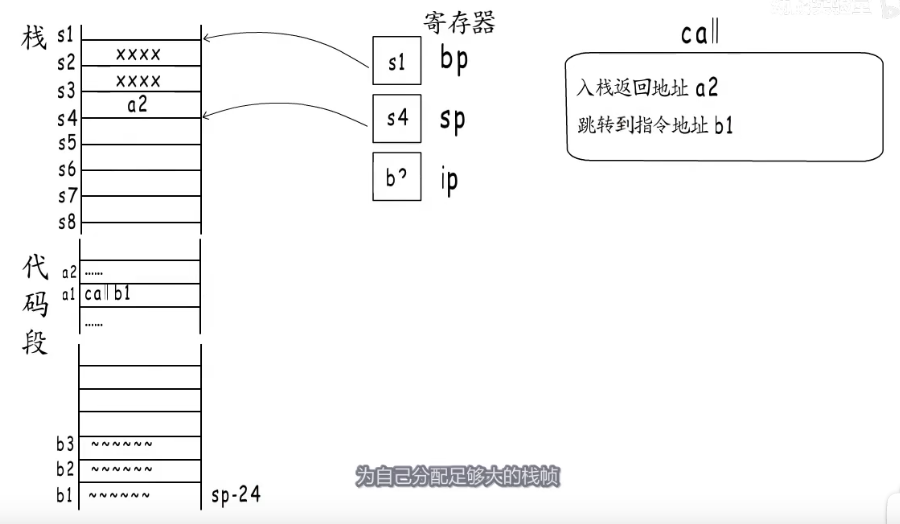
b1先分配足够大栈帧,所以栈指针挪到s7这里,b2这条指令要把调用者栈基s1存到sp+16字节的地方,接下来是b3,sp+16字节处,也就是函数B的栈基,把他存入bp寄存器,接下来就是执行函数B剩下的指令了。
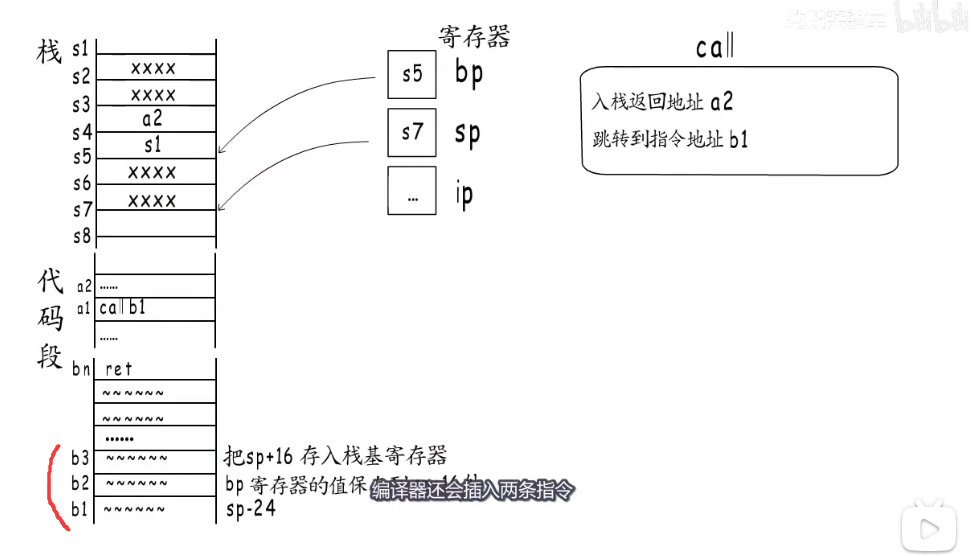
在执行ret指令前编译器还会插入两条指令,
第一条,指令恢复调用者A的栈基地址,之前被存储在sp+16字节这里,第二条,释放自己的栈帧空间,分配时向下移动了多少,释放时就向上移动多少。
然后就到了ret指令了。作用也是两点,第一,弹出call执行压栈的返回地址,第二,跳转到这个返回地址,这个时候就可以从a2这个地方继续执行了。
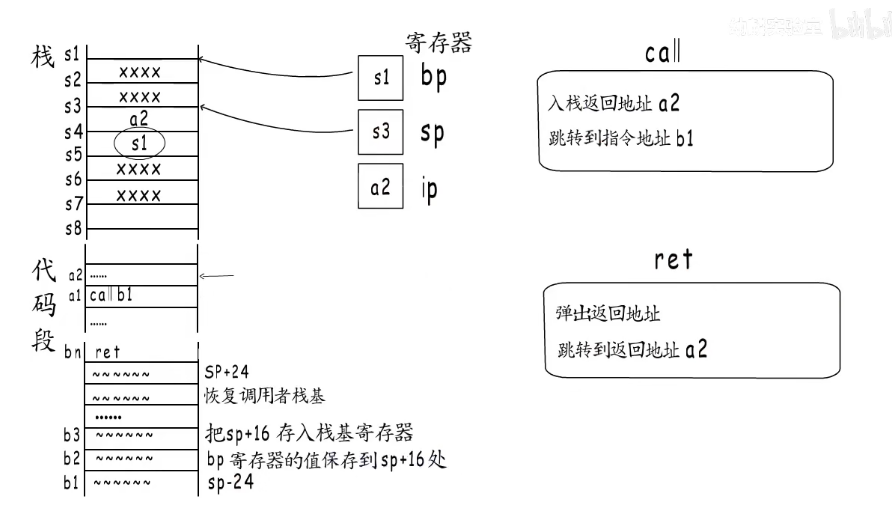
简单来说,函数通过call指令来实现跳转,而每个函数开始时会分配栈帧,结束前又会释放自己的栈帧,ret指令又会吧栈恢复到calll之前的样子。
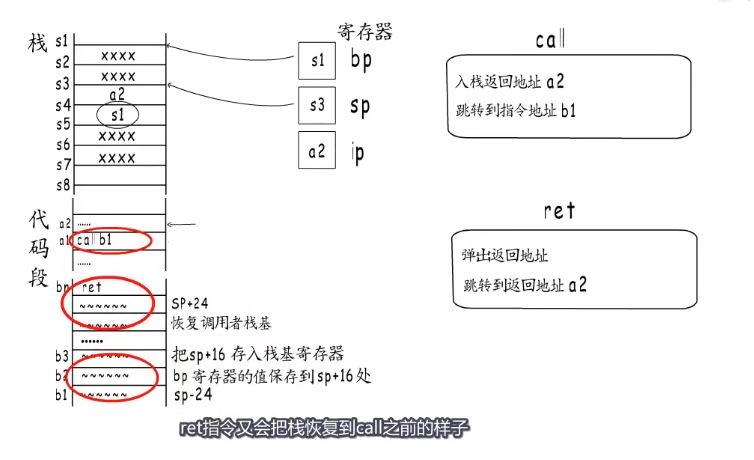
通过这些指令的配合能够实现函数的层层嵌套,,函数A调用函数B,B有调用C ,C又调用D 形成下图的栈
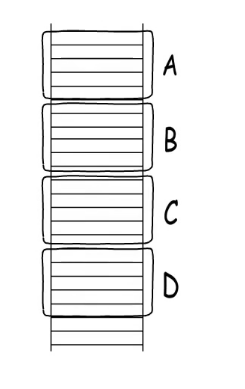
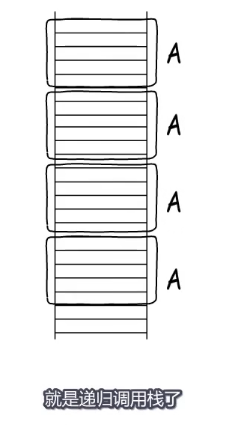
如果每次调用的都是A那就形成了递归的调用栈。
函数调用栈(二):传参和返回值
有参数的情况
现在写一个方法去交换传入的两个值:(失败案例)
package main
import "fmt"
func swap(a, b int) { // 交换值的方法
a, b = b, a
}
func main() {
a, b := 1, 2
swap(a, b) // 问题是这里传入的是拷贝值
fmt.Println(a, b) // 输出的还是1,2,交换的是拷贝值。
}可以通过函数调用栈看看问题出在哪里,
先看看main函数,先分配局部变量存储空间,a=1,b=2,局部变量的后面就是给被调用函数传入的参数,需要传入两个整形参数。传参就是值的拷贝,参数的入栈顺序由右至左,先入栈第二个参数,在入栈第一个参数,返回值也是一样。调用者栈帧后面是call指令存入的返回地址,再下面分配的就是swap函数栈帧了。
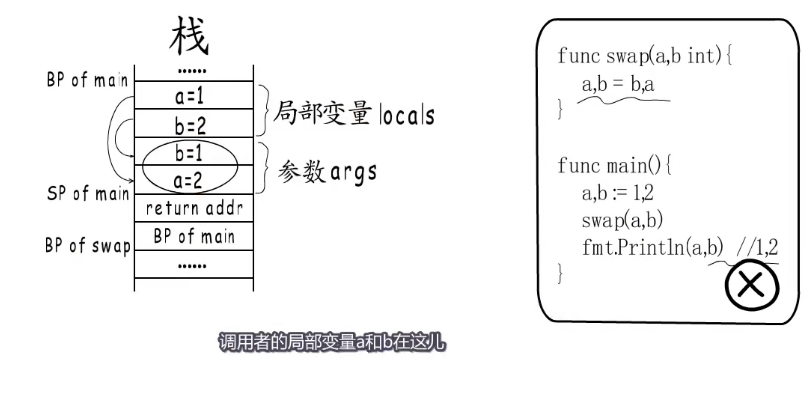
当swap执行到这里的时候,需要交换两个参数的值,他的参数是拷贝的a,b值,也就是参数,交换的也是拷贝的值参数,但是返回打印的是局部变量的值。
指针
还是刚刚的例子,通过指针指向局部变量的值,修改的也是局部变量的值。
package main
import "fmt"
func swap(a, b *int) {
*a, *b = *b, *a
}
func main() {
a, b := 1, 2
swap(&a, &b)
fmt.Println(a, b) // 输出2,1
}再次通过函数调用栈理解一下
指针拷贝的是值地址,存储的也是值的地址。
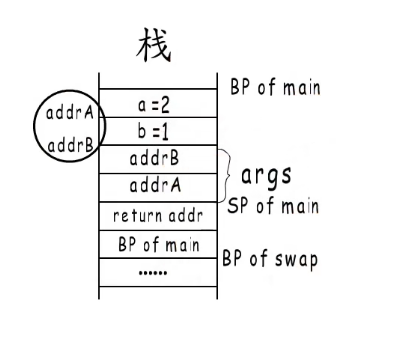
当函数执行到swap函数的时候传入值的地址,修改指向地址的参数,这一次就可以交换成功。
返回值
通常我们认为返回值是通过寄存器传递,但是go语言支持多返回值,所以在栈上分配返回值空间更合适,看一个例子
package main
import "fmt"
func incr(a int) int {
var b int
defer func() { // defer函数是在整个函数执行结束之前执行。
a++
b++
}()
a++
b = a
return b
}
func main() {
var a, b int
b = incr(a) // 匿名返回值的情况
fmt.Println(a, b) //输出 0,1;这里的a,b按照道理来说应该是输出 2,2才是
}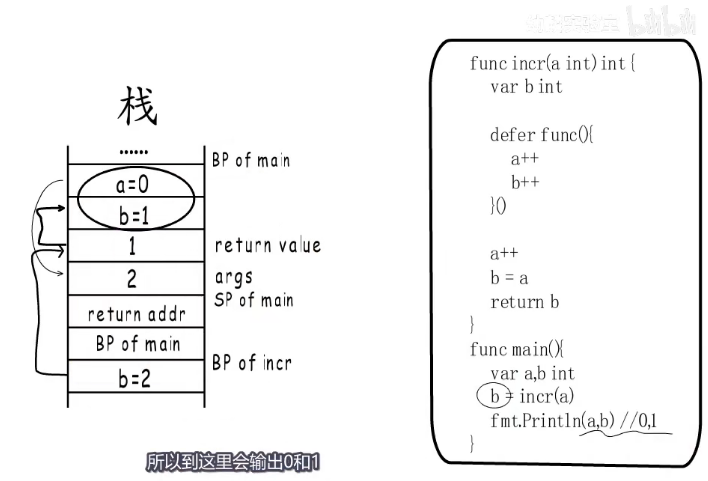
注意:程序在执行defer函数之前会先进行赋值,当执行到return的时候局部变量b的值拷贝到返回值空间,然后执行defer函数,执行结束后把返回空间的值赋值给b,所以这里输出的为0,1
例2
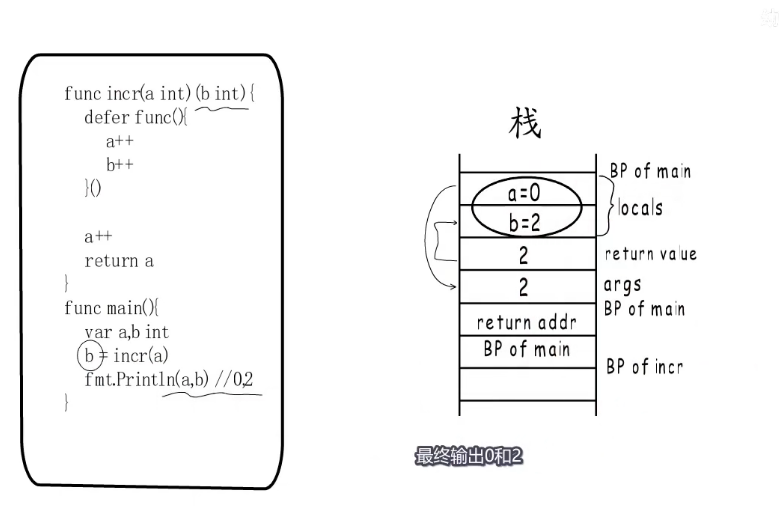
我们把这里返回值改成命名返回值:
package main
import "fmt"
func incr(a int) (b int) { // 修改的是这里
defer func() { // defer函数是在整个函数执行结束之前执行。
a++
b++
}()
a++
b = a
return b
}
func main() {
var a, b int
b = incr(a)
fmt.Println(a, b) // 输出 0,2
}在函数栈的理解下是怎样运行的呢?
main函数的栈帧和上一个例子完全相同,但是到incr函数栈帧这里,没有局部变量,b就是返回空间的值。这里最终输出 0,2
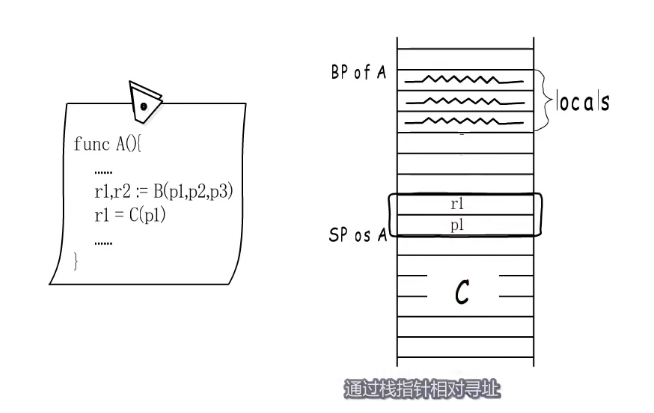
调用多个函数的问题
如果一个函数调用了多个函数,我们知道不同的函数占用的栈空间是不同的,go语言中函数栈帧是一次性分配的,如果局部变量占一点,后面需要以最大的参数返回值空间为标准来分配空间,才能满足所有被调用函数的需求,所有如果遇到占用空间少的函数时,是通过栈指针相对寻址自己的参数和返回值 。
go闭包
在go语言中函数就是头等对象,可以作为参数传递,可以做函数的返回值,也可以绑定到变量。go语言称这样的参数、返回值或变量为function value 。
函数的指令在编译期间生成,而function value 本质上是一个指针,但是并不直接指向函数指令入口,而是指向一个runtime.funcval结构体,这个结构体里只有一个地址,就是这个函数指令的入口地址。
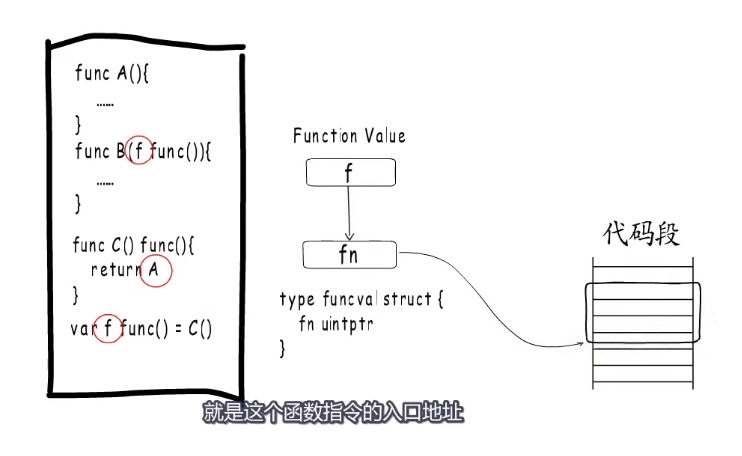
例子:
函数A赋值给f1和f2,这个时候编译器会做出优化,让f1和f2共用一个funcval结构体。f1和f2本身存储的是addr2执行起始地址,找到addr1为funcval结构体,拿到函数入口地址然后跳转执行,这里是一个二级指针来进行的调用。
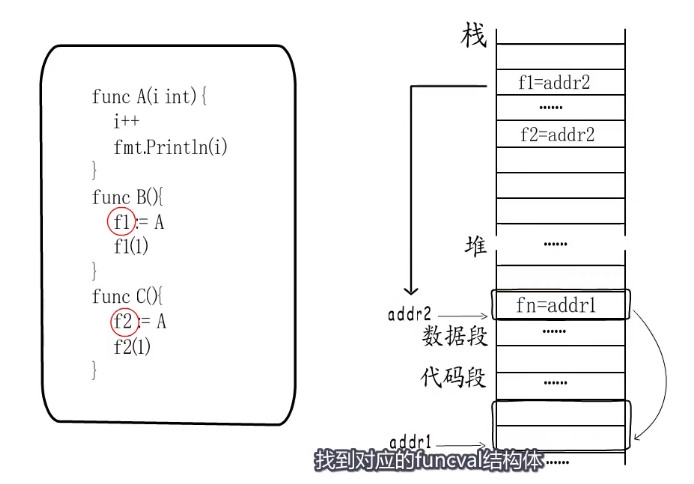
使用二级指针主要是为了处理闭包的情况。
go方法
package main
import "fmt"
// 定义类型A
type A struct {
name string
}
// 关联一个方法
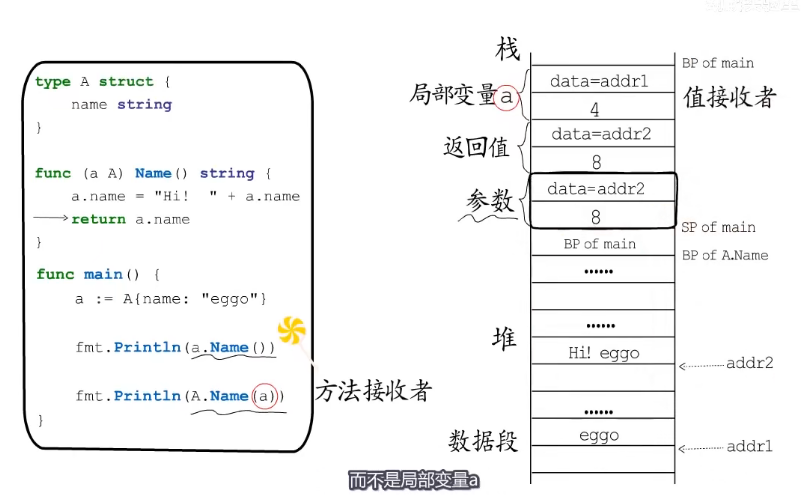
func (a A) Name() string {
a.name = "Hi " + a.name
return a.name
}
func main() {
a := A{name: "eggo"}
fmt.Println(a.Name()) //就可以通过这个类型A的变量来调用这个方法,实际上和下面的调用方法是一样的。
// 输出 Hi eggo
fmt.Println(A.Name(a)) // 这里是方法的接受者,
// 输出 Hi eggo
}
go语言中函数类型只和参数与返回值相关
func NameOfA(a A) string {
a.name = "Hi!" + a.name
return a.name
}
func main() {
t1 := reflect.TypeOf(A.Name)
t2 := reflect.TypeOf(NameOfA)
fmt.Println(t1 == t2) // true,证明了方法本质上就是普通的函数
}指针
// 定义类型A
type A struct {
name string
}
// 关联一个方法
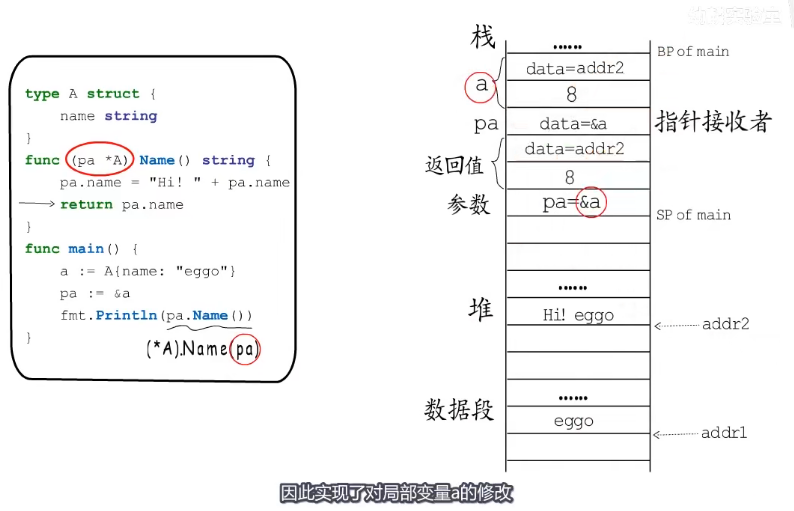
func (pa *A) Name() string {
pa.name = "Hi " + pa.name
return pa.name
}
func main() {
a := A{name: "eggo"}
pa := &a
fmt.Println(a.Name()) // 输出 Hi eggo 因为是打印的局部变量的存储的值。局部变量存储的值
fmt.Println(pa.Name()) // 输出 Hi Hi eggo 这里打印的是局部变量地址指向的内容。局部变量存储的地址。
}
如果在编译期间不能拿到地址的字面量,不能通过语法糖来进行转换了。所以不能通过编译。
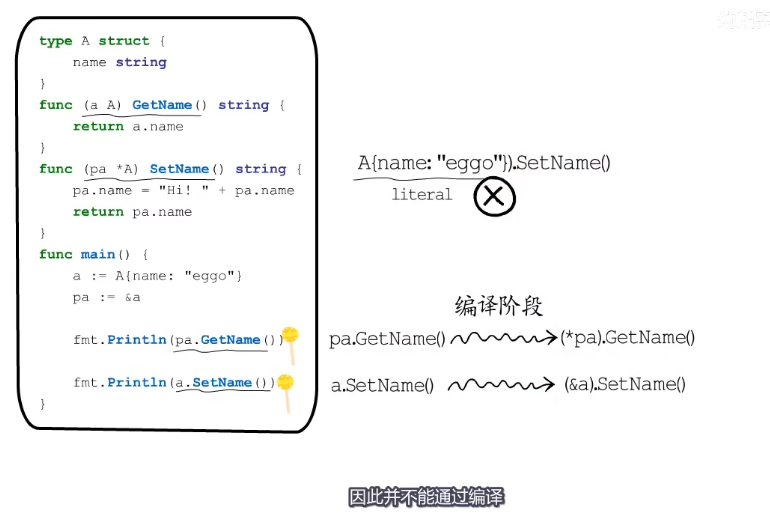
方法赋给变量
go语言中函数作为变量、参数、返回值时都是以Function Value的形式存在的。
闭包也只是通过捕获列表的Function Value而已
// 定义类型A
type A struct {
name string
}
// 关联一个方法
func (a A) GetName() string {
return a.name
}
func main() {
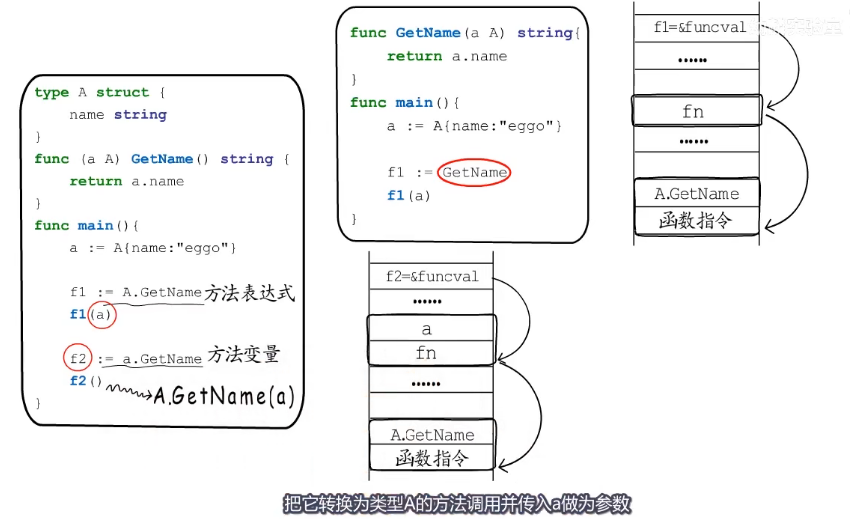
a := A{name: "eggo"}
f1 := A.GetName //f1就是一个方法表达式实际上和其他的代码
f1(a)
f2 := a.GetName // 方法变量,
// 这里就相当于形成了双指针,形成了闭包。
// 这里的f2只是一个局部变量,但是和f1的生命周期是一致的,所以编译器会做出优化,把它转化为类型A的方法调用并传入a作为参数
f2()
}f1实际上和这段代码相同
func GetName(a A) string {
return a.name
}
func main() {
a := A{name: "eggo"}
f1 := GetName
f1(a)
}所以f1本质上其实也是一个 Function Value 也就是一个funcval结构体的指针
f2是是一个方法变量
再举一个例子
这里的f3是一个闭包结构
// 定义类型A
type A struct {
name string
}
// 关联一个方法
func (a A) GetName() string {
return a.name
}
func GetFunc() func() string {
a := A{name: "eggo in GetFunc"}
return a.GetName // 这里返回的其实就是A.GetName(a)
}
func main() {
a := A{name: "eggo in main"}
f2 := a.GetName // 可以看到和GetFunc是一致的
fmt.Println(f2()) // eggo in main
f3 := GetFunc()
fmt.Println(f3()) // eggo in GetFunc
}总结:从本质上来讲,方法表达式和方法变量都是Function Value
脱胎换股的defer
defer会在函数返回之前倒叙执行
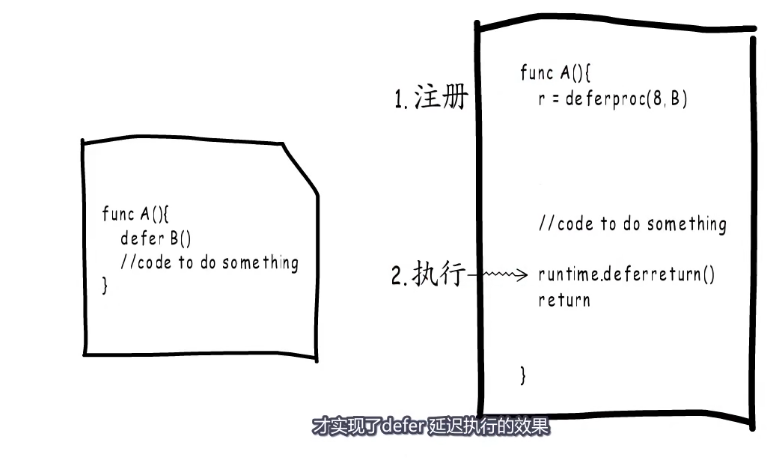
defer执行对应两部分内容,deferproc负责把要执行的函数信息保存起来,我们称之为 defer注册,deferproc函数会返回0。
defer注册后程序会继续执行后面的逻辑,直到返回之前通过deferreturn执行注册的defer函数。正式因为先注册,后调用,才实现了defer延迟执行的效果。(可能是编译器,编译的结果)
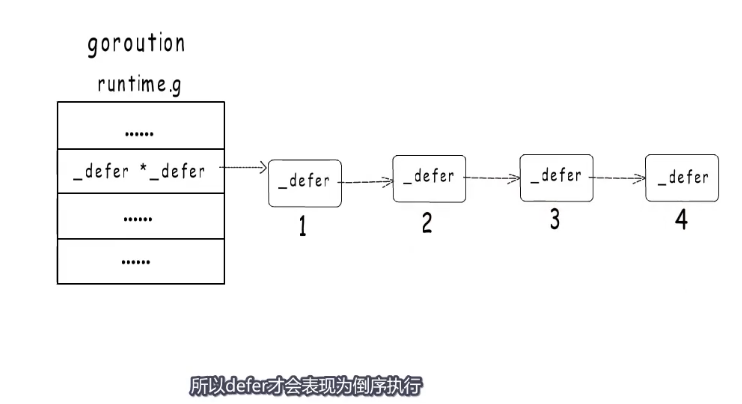
defer信息会注册到一个链表,而当前执行的 goroutine持有这个链表的头指针,每个goroutine在运行时都有一个对应的结构体 g其中有一个字段指向defer链表头,而 defer链表连起来的是一个一个 _defer结构体,新注册的defer会添加到链表的头,执行的时候也是从头开始,所以 defer才会表现为倒序执行。
defer结构体

type _defer struct {
siz int32 // 参数和返回值共占用多少字节
started bool // 是否已经执行
sp uintptr // 注册这个defer的函数栈指针
pc uintptr // deferproc的返回地址
fn *funcval // 是要注册的function value
_panic *_panic
link *_defer //连接到前一个注册的_defer结构体
}先注册,后执行
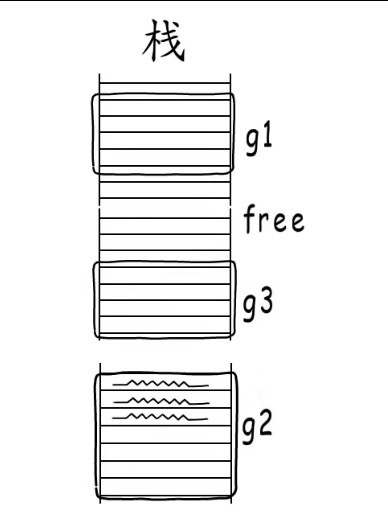
例子:deferproc函数执行时,需要堆分配一段空间,用于存放defer结构体,添加完成后这个 _defer结构体就被添加到 defer链表头,deferproc注册结束。
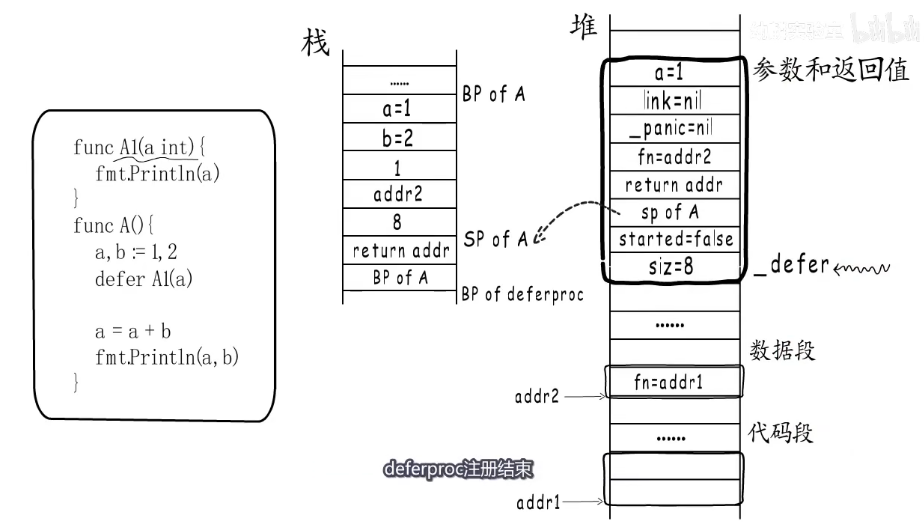
实际上go语言会预分配不同规格的defer池,执行的时候会从空闲的 _defer中取出一个来用。没有合适的就重新分配。
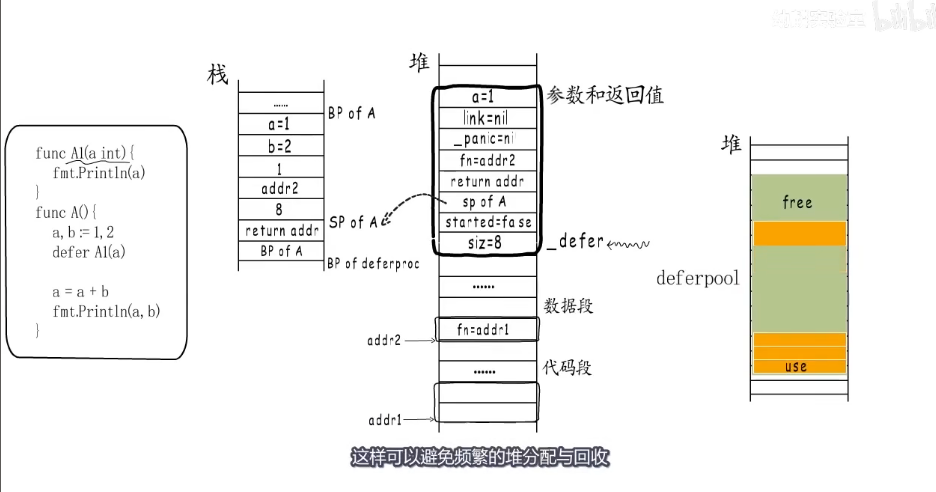
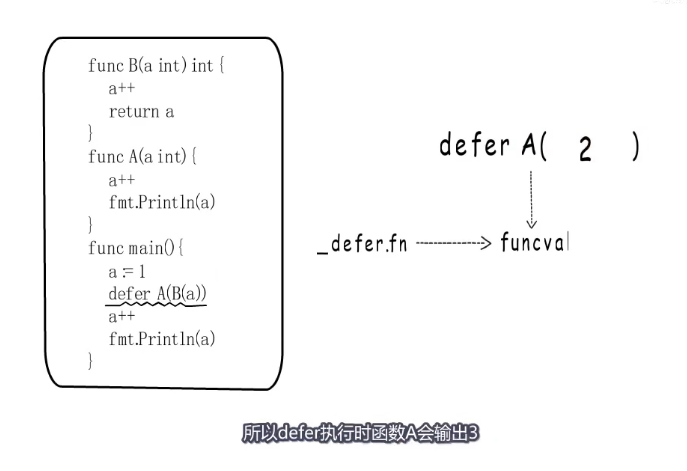
defer执行例子:
defer注册函数是A,defer链表存储的也是A的funcval指针,因为注册的时候需要保存A的参数,就必须拿到B的返回值,所以这里的B是顺序执行。B返回2
func B(a int) int {
a++
return a
}
func A(a int) {
a++
fmt.Println(a) // 3
}
func main() {
a := 1
defer A(B(a)) //defer注册函数是A,defer链表存储的也是A的funcval指针,因为注册的时候需要保存A的参数,就必须拿到B的返回值,所以这里的B是顺序执行。B返回2
a++
fmt.Println(a) // 2
}
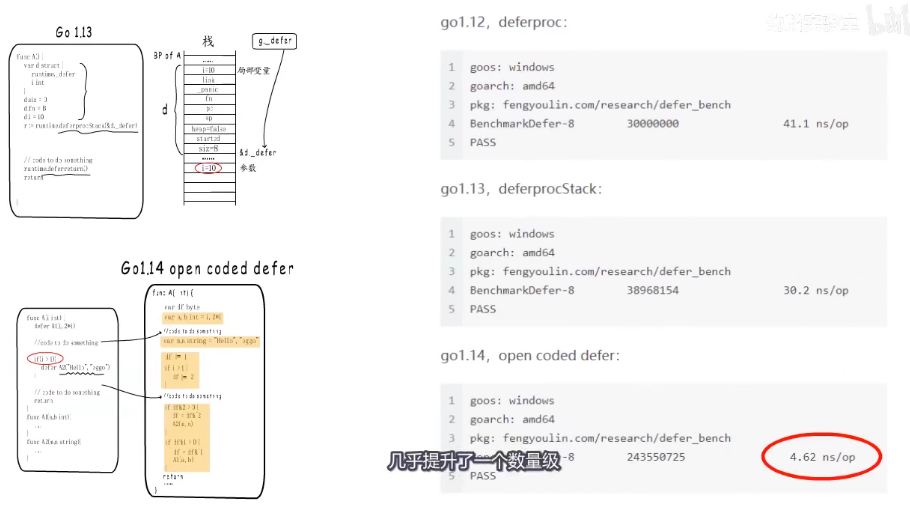
这里大致讲解了go 1.12 版本的 defer基本的设计思路,存在比较明显的问题,就是慢。
第一个原因是defer结构体的堆分配,即使有预分配的deferpool,也需要去堆上获取与释放,而且参数还要在堆上来回拷贝。
第二个原因是使用链表注册defer信息,而链表本身的操作就比较慢,所以在1.13和1.14中进行了优化。
脱胎换股的defer(二)
这里可以进阶看
1.13版本的defer性能提升了30%
1.14版本提升了一个数量级,代价就是,panic变得更慢了,但是 panic发生的几率要比 defer低。
panic和recover
经过上面的学习已经知道,在当前执行的goroutine中有一个 defer链表的头指针,其实它也有一个panic链表头指针。基本和defer一样
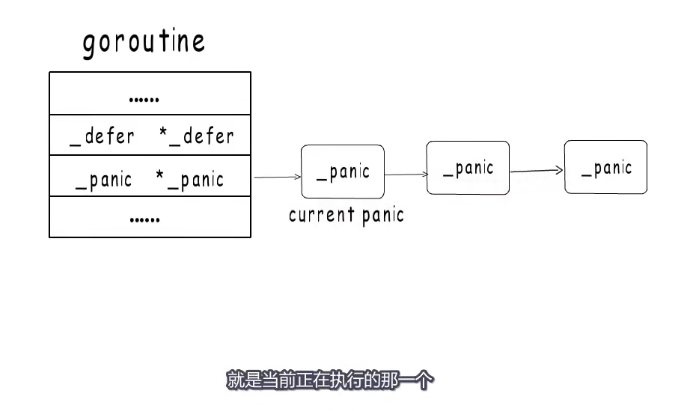
例子:
执行到箭头这里时发生了panic后面的代码就不会执行了,而是进入panic处理逻辑,
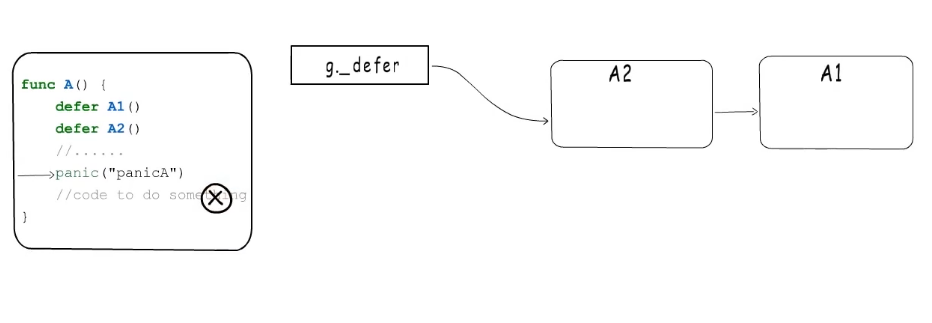
这里会在panic链表中增加一项,这里记为panicA就是当前执行的panic,然后执行defer链表。
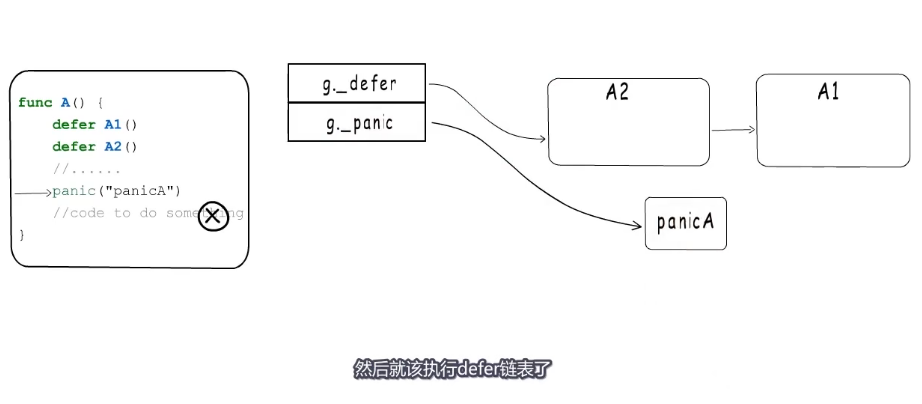
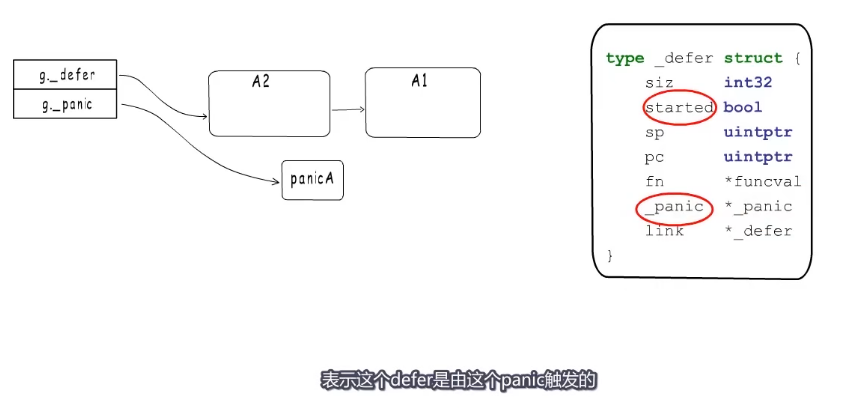
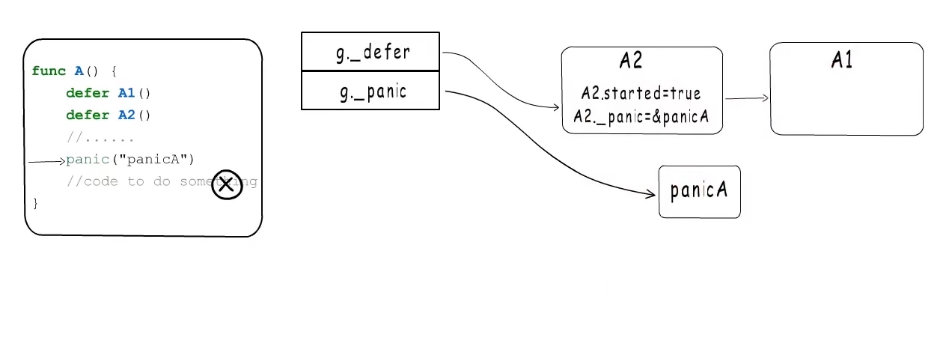
panic执行defer时会把started置为true,并把_panic字段指向当前执行的panic
如果函数A2能正常结束,就继续执行下一个defer,如果再次发生panic,后面的代码也不会执行,然后再panic链表头插入一个新的panic
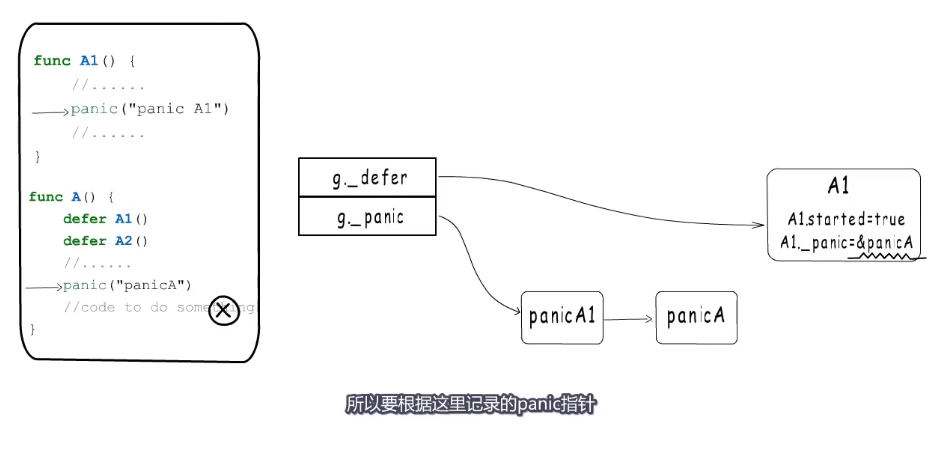
这个时候panicA被终止,A1这一项也要被移除,defer链表为空。接下来就该打印panic异常信息了。打印信息时是从panic发生的顺序逐个输出。
关注点:
- 第一个是panic执行defer函数的方式,是先标记,后释放,目的是为了终止之前发生的panic
- 第二个是异常信息的输出方式,所有还在panic链表上的项都会被输出,顺序与panic发生的顺序一致。
_panic结构体
type _panic struct {
argp unsafe.Pointer // 存储当前要执行的defer的函数参数地址
arg interface{} // panic函数自己的参数
link *_panic // 链接到之前发生的panic
recovered bool // 表示panic是否被恢复
aborted bool // 标识panic是否被终止
}panic打印信息时会从链表尾部开始,也就是按照panic发生的顺序逐个输出。
recover
recover函数逻辑很简单,它只做一件事,就是把当前执行的panic置为已恢复,也就是把它的recovered字段置换为true其他的都不管。
这里还是需要多听听。
类型系统
type T struct {
name string
}
func (t T) F1() {
fmt.Println(t.name)
}
func main() {
t := T{name: "eggo"}
t.F1() // 方法本质上就是函数
}方法本质上就是函数,只不过在调用时接受者会作为第一个参数传入,在编译的时候没有问题,但是在执行的时候反射、接口动态派发、类型断言,这些语言特性或者机制如何动态的获取数据类型信息呢?
我们定义的类型一般都是自定义类型,都需要定义元素信息,成为类型元数据,每种类型的元数据都是全局唯一的,一起构成了go语言的“类型系统”。
每个类型元数据都需要记录类型名称、大小、对其边界、是否是自定义类型等,是每个元数据都需要记录的信息,所以都放到了runtime._type结构体中作为每个类型元数据的Header, 在_type之后存储的才是额外需要描述的信息,使用*_type可以指向其存储的元素的类型元数据如果是string就指向string类型的元数据。
如果是自定义类型,后面还会有一个uncommontype结构体
type _type struct {
size uintptr
ptrdata uintptr
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
}
type slicetype struct {
typ _type
elem *_type // 指向上面的类型
}
// 自定义类型
type uncommontype struct {
pkgpath nameOff // 记录类型所在的包路径
mocount uint16 //记录了类型关联到多少个方法
moff uint32 // 记录了这些方法元数据组成的数组的偏移值
}自定义类型例子:
我们给 myslice自定义了Len和Cap两个方法
type myslice []string
func (ms myslice) Len() {
fmt.Println(len(ms))
}
func (ms myslice) Cap() {
fmt.Println(cap(ms))
}通过uncommontype我们可以通过moff找到方法元数据在哪里,比如方法Len地址是addrA那地址加上moff偏移值就可以找到myslice关联的方法元数据数组。
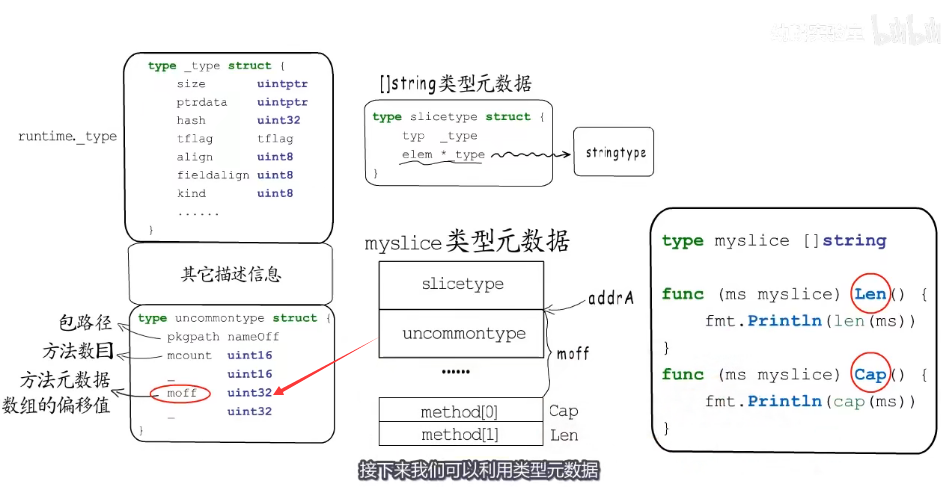
使用类型元数据,看看其他的写法,
例子:
MyType1 这种写法叫做给int32类型起个别名,实际上MyType1和int32会关联到同一个类型元数据。
type MyType1 = int32 //这种写法叫做给int32类型起个别名
type MyType2 int32 //这种写法是基于已有类型创建一个新类型,相当于自立门户。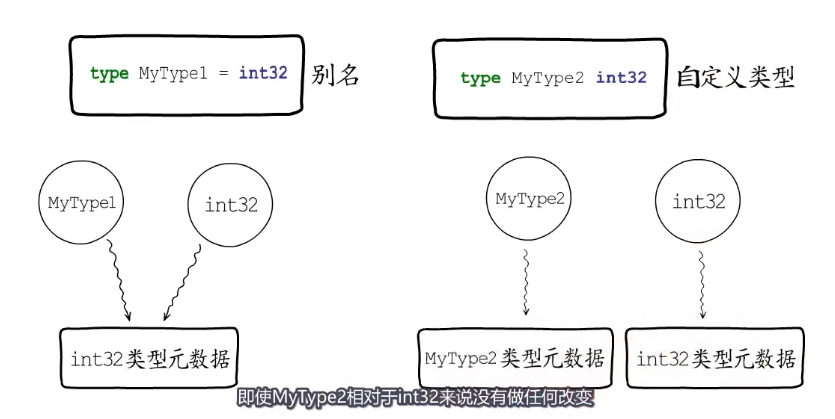
接口(interface)
空接口
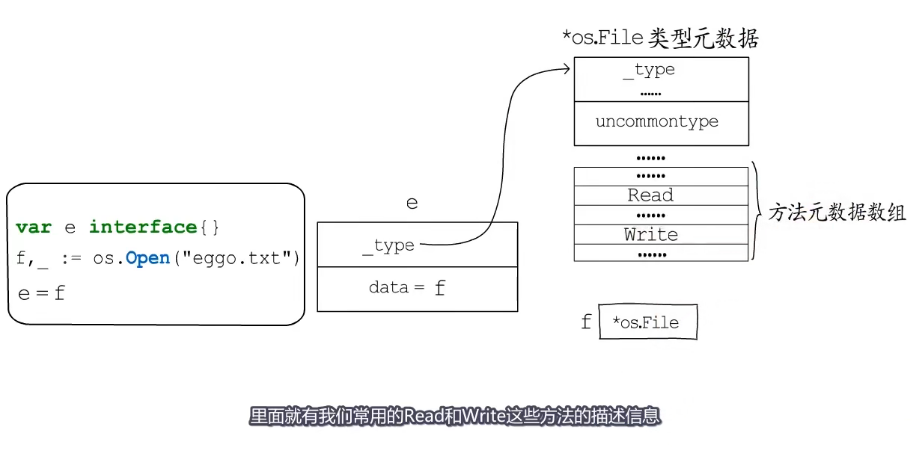
先看看空接口,空接口类型可以接受任意类型的数据,只要记录这个数据在哪里,是什么类型的就足够了。
_type指向接口的动态类型元数据,data指向接口的动态值
空接口在赋值以前_type和data都是nil

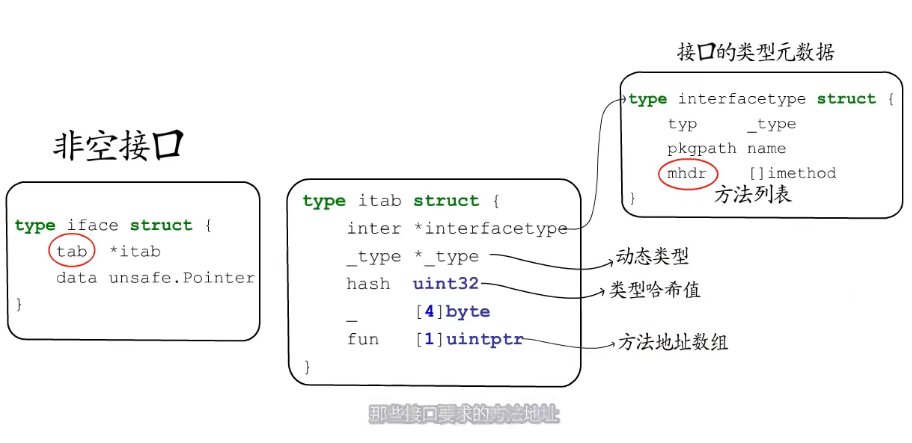
非空接口
非空接口就是有方法列表的接口类型,一个变量想要赋值给一个非空接口类型,必须要实现该接口要求的所有方法才行
type iface struct {
tab *itab // 指向 itab 结构体
data unsafe.Pointer
}
type itab struct {
inter *interfacetype // 指向 interface 接口元数据
_type *_type // 指向接口的动态类型元数据
hash uint32 // 从动态类型元数据中拷贝来的类型哈希值,用于快速判断类型是否相等时使用
_ [4]byte
fun [1]uintptr // 方法地址数组
}
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod // 接口要求的方法列表就记录在这里
}
例子:
var rw io.ReadWriter
f,_:=os.Open("eggo.txt")
rw = f在赋值以前data为nil,tab也为nil。如果把f赋值给rw此时rw的动态值就是f而tab也会指向一个itab的结构体。
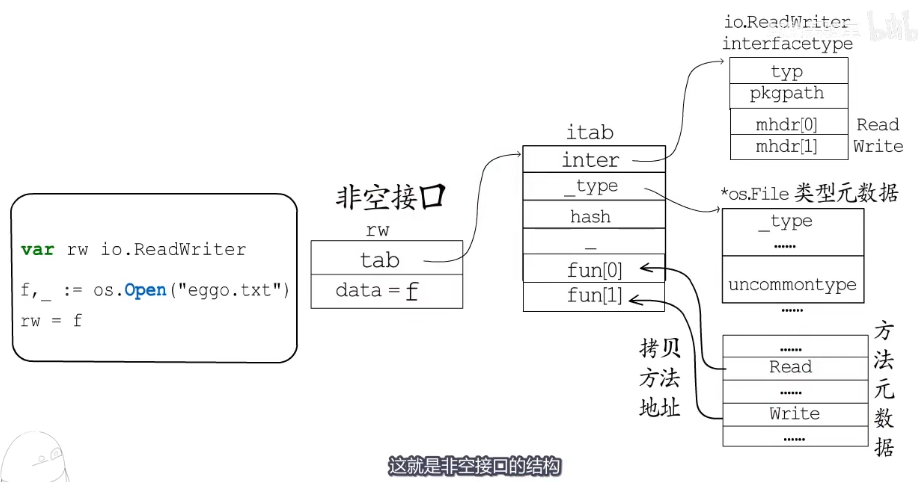
itab其他点
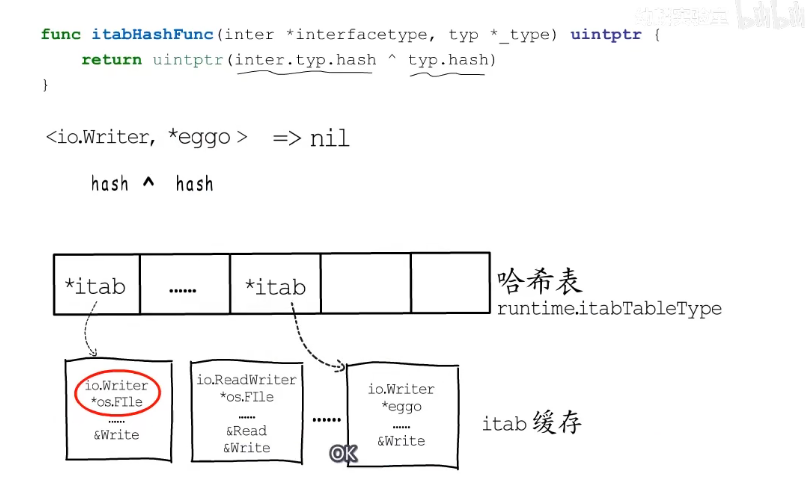
一点接口类型确定,动态类型确定了,那itab的内容就不会改变了,所以itab结构体一般是可复用的,go语言会把用到的itab结构体缓存起来,并以接口类型和动态类型的组合为key,以itab结构体指针为value,构造一个hash表用于存储itab表的缓存信息。
类型断言
接口可以分为空接口和非空接口,类型断言作用在接口值之上,可以是空接口或非空接口,而断言的目标类型可以是具体类型或非空接口类型。所以可以组合出四种断言类型。
第一种:空接口.(具体类型)
空接口.(具体类型)
var e interface{}
r, ok := e.(*os.File) // e.(*os.File)是要判断e的动态类型是否是*os.File 其实只要确定e的_type是否指向*os.File的类型元数据就好了,go语言中每一种类型的元数据都是全局唯一的。
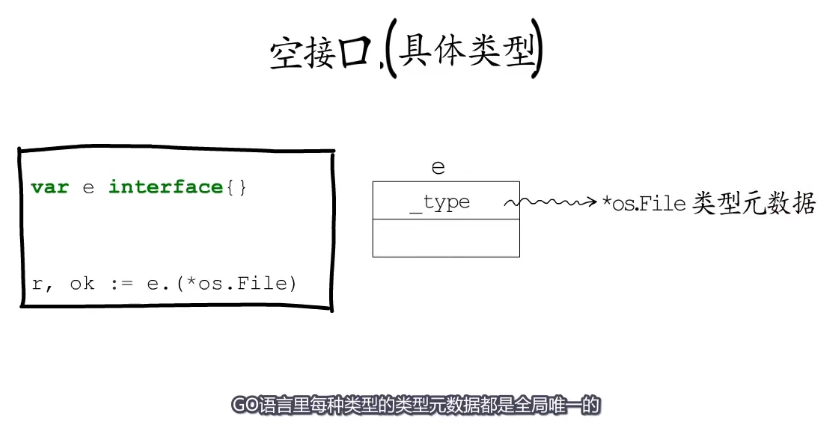
如果是
var e interface{}
f, _:=os.Open("test.go")
e = f
r, ok := e.(*os.File)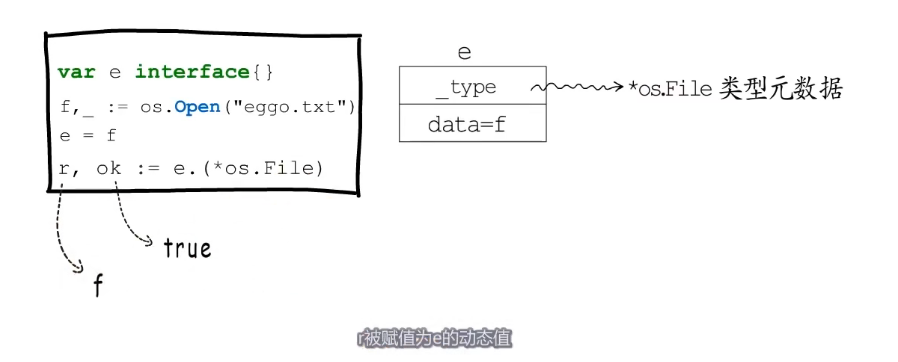
第二种 :非空接口.(具体类型)
例子
rw.(*os.File)是要判断rw的动态类型是否为*os.File.
var rw io.ReadWriter
f,_ := os.Open("eggo.txt")
rw = f
r,ok := rw.(*os.File) // rw.(*os.File)是要判断rw的动态类型是否为*os.File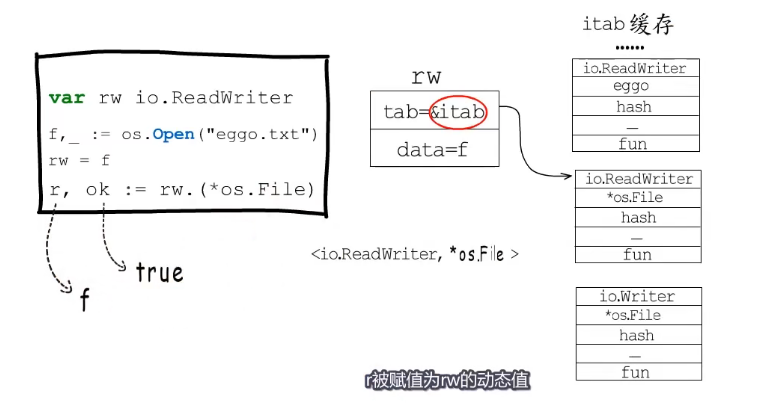
var rw io.ReadWriter
f := eggo{name:"eggo"}
rw = f
r,ok := rw.(*os.File) // rw.(*os.File)是要判断rw的动态类型是否为*os.File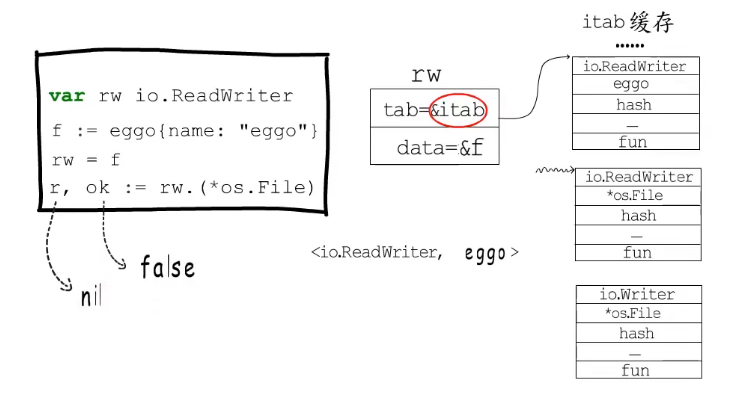
第三种:空接口.(非空接口)
var e interface{}
rw,ok := e.(io.ReadWriter)e.(io.ReadWriter)是要判断e的动态类型是否实现了io.ReadWriter接口
var e interface{}
f,_ := os.Open("test.txt")
e = f
rw,ok := e.(io.ReadWriter)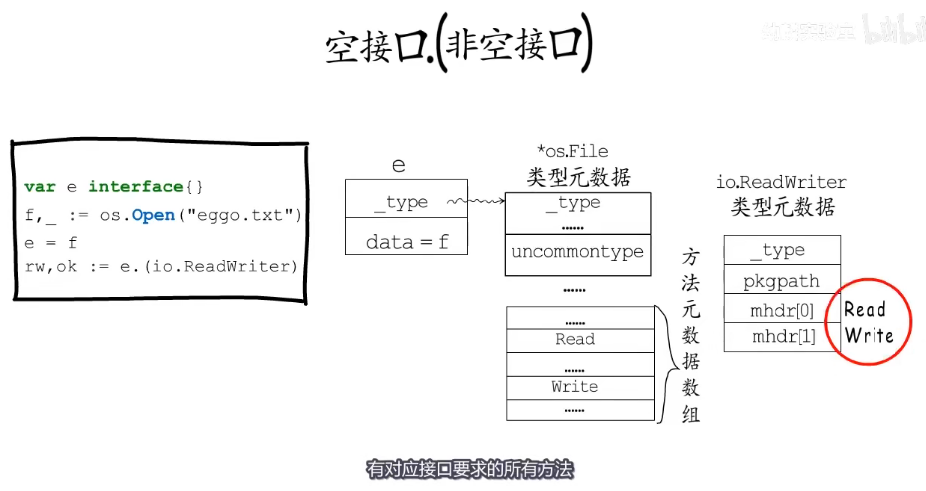
这里可以用itab缓存,可以先在itab中查找一下,如果没有io.ReadWriter和*os.File对应的itab结构体,再去检查*os.File的方法列表。如果查找到了对应的itab指针,也需要判断itab.fun[0]是否等于0,因为断言失败的类型组合其对应的itab结构体也会被缓存起来,只是会把itab.fun[0]置为0,用以标识这里的动态类型并没有实现对应的接口。
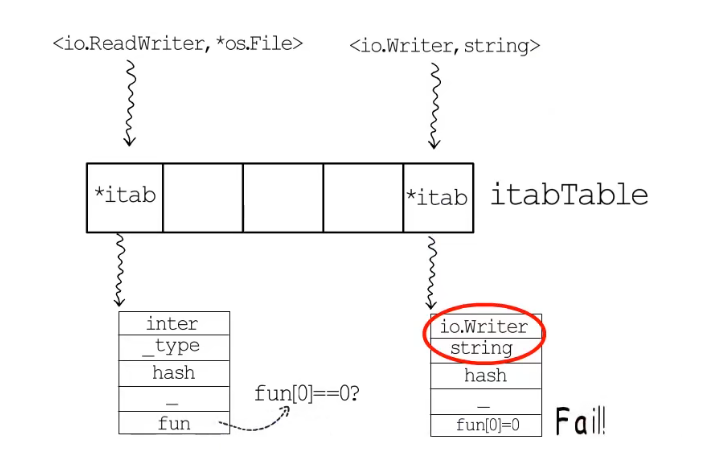
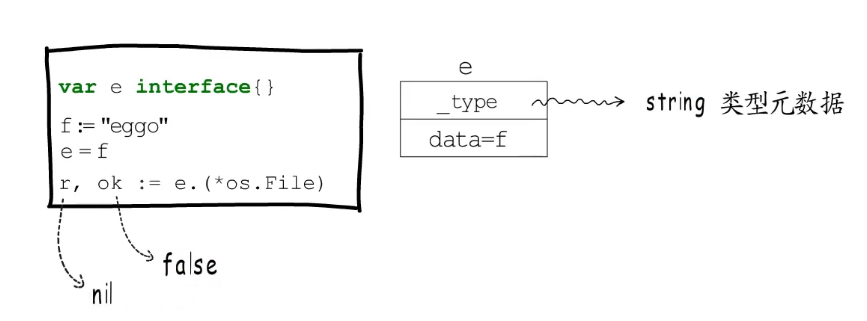
如果类型为string:
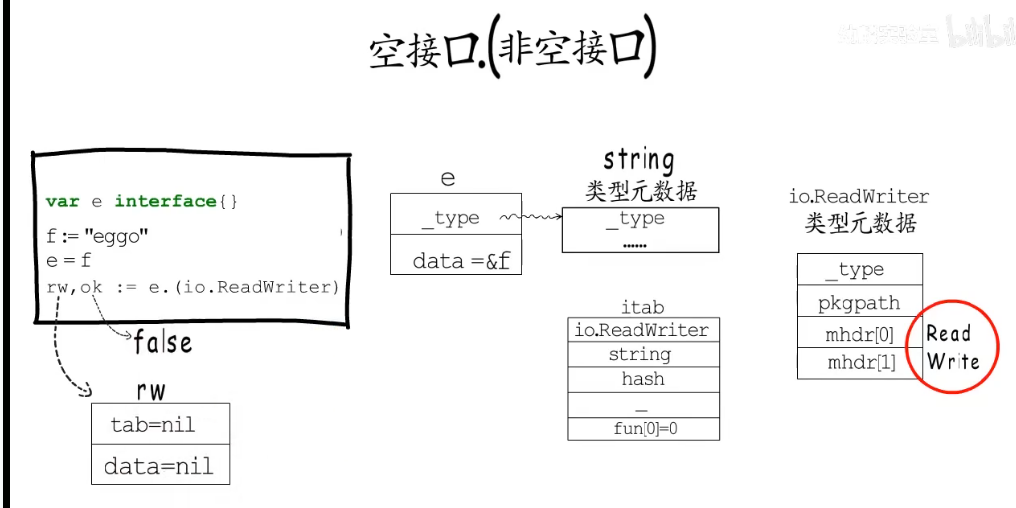
第四种:非空接口.(非空接口)
!未完需要再次听。
reflect反射
反射的作用就是把类型元数据暴露给用户使用
介绍了runtime包中类型接口的结构,但是这些类型都是未导出的,所以reflect包中自己又定义了一套,这些类型的定义在两个包中是保持一致的。
reflect包中提供一个TypeOf函数用于获取一个变量的类型信息,
func TypeOf(i interface{}) Type { // 这里接受一个空接口类型的参数,返回一个reflect.Type类型的值
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType{eface.typ}
}例子:
在eggo包中定义一个类型,
package eggo
type Eggo struct {
Name string
}
func (e Eggo) A() {
println("A")
}
func (e Eggo) B() {
println("B")
}在main包中使用这个类型。
import (
"reflect"
"./eggo"
)
func main() {
a := eggo.Eggo{Name: "eggo"}
t := reflect.TypeOf(a)
//Eggo 2
println(t.Name(), t.NumMethod())
}通过反射看看这个类型有多少个可以导出的方法
!!!也没有看完呢
GPM(一)goroutine的执行过程
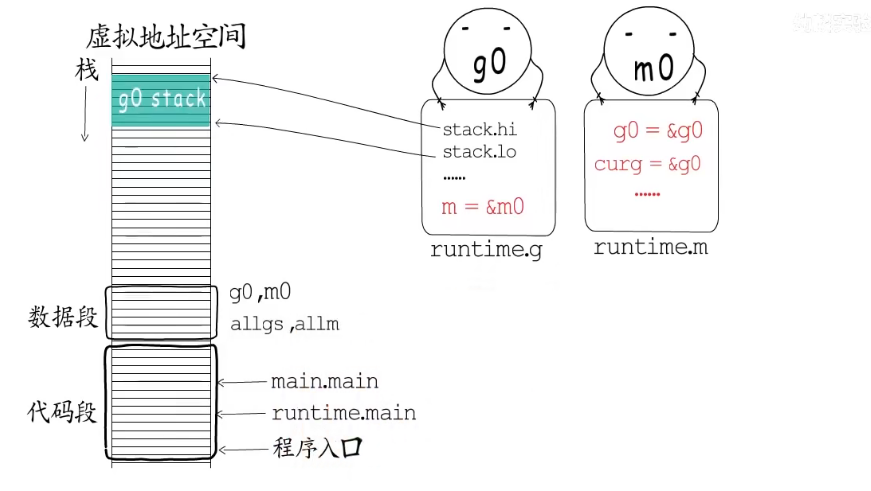
在不同平台下,程序执行的入口是不同的,在进行检查和初始化等工作后,会以runtime.main为执行入口创建main goroutine,main goroutine执行起来后才会调用main.main
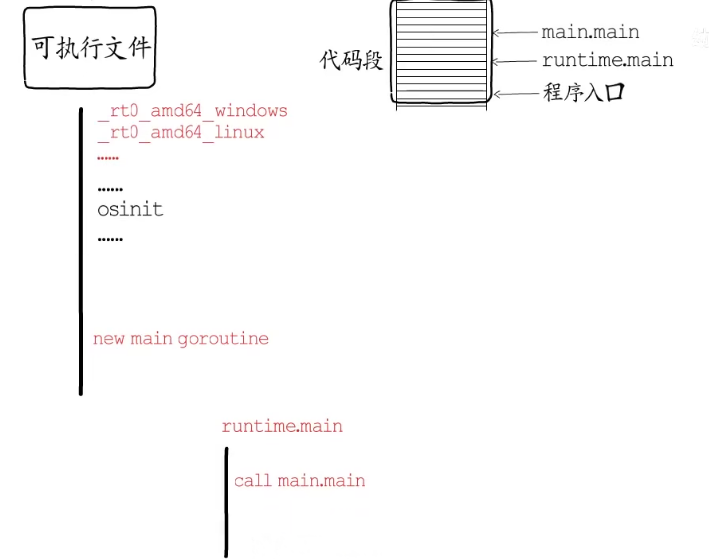
在go语言中协程对应的数据结构是runtime.g,工作线程对应的数据结构是runtime.m
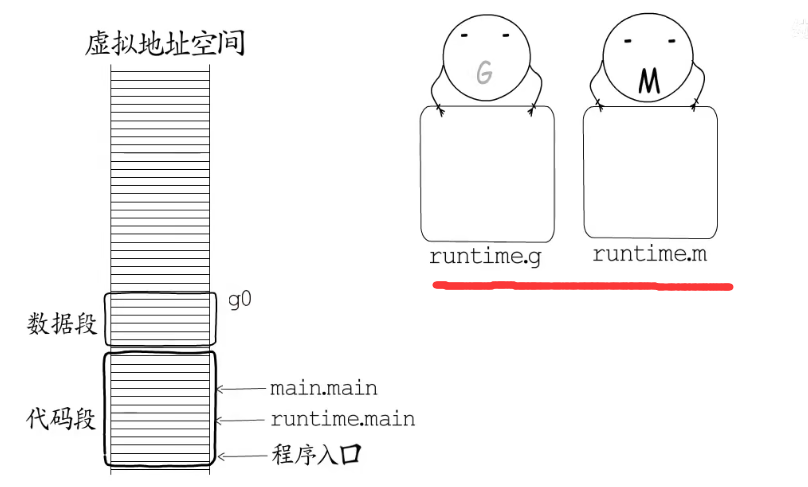
全局变量g0就是主协程对应的g,和其他的协程不同它的协程栈实际上是在主协程栈上分配的。全局变量m0就是主线程对应的m。g0持有m0的指针,m0里也记录着g0的指针。一开始m0上执行的协程正是g0,m0和g0就联系起来了。