因为对博客壁纸不太满意,搜寻了大多数壁纸,但都不是很好看,最终锁定了必应的每日壁纸。决定爬取下来用于博客的美化。
分析网页
思路:查看url的生成规律,得到页面的rul,通过xpath得到图片的src连接,就能得到单个页面的所有图片的src链接的一个列表。通过循环获得图片。
代码
需要下载的页
先写一个方法获得自己需要爬取的页码
def get_user_input():
'''
输入需要下载的页码
返回一个页码的list
'''
print('请输入需要下载的页码,像这样"4,6,8",用逗号分开,或者中间加个减号表示范围,像这样"4-7"')
user_input = input()
if len(user_input) == 1:
start_end_ = user_input
print('需要下载的页码为:' + str(start_end_))
else:
if '-' in user_input:
test = list(user_input.split("-"))
start_end_ = list(range(int(test[0]), int(test[1]) + 1))
print('需要下载的页码为:' + str(start_end_))
else:
start_end_ = [int(n) for n in user_input.split(",")]
print('需要下载的页码为:' + str(start_end_))
return start_end_生成需要爬取的url
打开必应壁纸的链接发现每页的链接为:
https://bing.ioliu.cn/?p=1
https://bing.ioliu.cn/?p=2
...自动生成url链接方法
def get_page_urls():
'''返回需要爬取的url'''
all_page_urls = []
start_end_ = get_user_input()
for num in start_end_:
all_page_urls.append('https://bing.ioliu.cn/?p={}'.format(str(num)))
return all_page_urls获取图片和名称
f12查看图片链接可以看到图片的地址,复制xpath地址
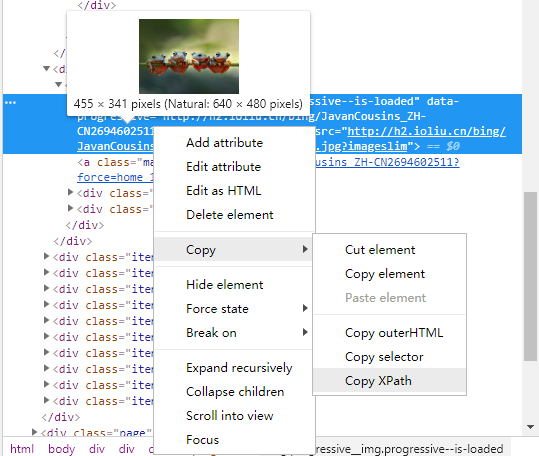
# 发现图片链接均为以下形式:
# /html/body/div[3]/div[2]/div/img
# /html/body/div[3]/div[5]/div/img
# 图片名称为
# /html/body/div[3]/div[2]/div/div[1]/h3/text()
# /html/body/div[3]/div[5]/div/div[1]/h3直接获得图片的所有链接,得到一个列表,通过循环就可以获得图片了2333.
img_url = html.xpath('//img/@src')获取图片
def get_imges(img_list,header):
img_list = img_list.replace('640x480', '1920x1080')
img = requests.get(img_list, headers=header).content
return img但是图片名称不好匹配,xpath得到的div中间有个数字,不好把握,写个方法直接循环得了。
def imgs_name(html,img_number,page_number):
p = re.compile(r'[-,$()#+&*,/:]')
html_text = html.xpath("/html/body/div[3]/div[" + str(img_number) + "]/div/div[1]/h3/text()")[0]
html_text_format = re.sub(p,"",html_text)
img_name = (str(int(page_number) * 12 + img_number) + '_' + str(html_text_format) + '.jpg')
print("下载",img_name)
return img_name通过主方法循环调用方法
if __name__ == '__main__':
header = {'User-Agent': 'w'}
page_number = 0
start_end = get_page_urls()
sleep_time = 0
for page_url in start_end:
img_number = 1
res = requests.get(page_url, headers=header).text
html = etree.HTML(res)
img_url = html.xpath('//img/@src')
if not os.path.exists('./bing_wallpaper2'):
os.makedirs('./bing_wallpaper2')
print('正在下载第{}页图片'.format(start_end[page_number]))
for img_list in img_url:
img = get_imges(img_list,header)
img_name = imgs_name(html,img_number,page_number)
with open('./bing_wallpaper2/' + img_name, 'wb') as save_img:
# 写入图片数据
save_img.write(img)
img_number += 1
time.sleep(8)
page_number += 1因为必应有自己的反扒机制,如果爬行太快,会被禁用ip地址,出现403的报错。所以每次爬行一个页面最好是停留一段时间,time.sleep()。
脚本完整代码
import requests
from lxml import etree
import os
import time
import re
def get_user_input():
'''
输入需要下载的页码
返回一个页码的list
'''
print('请输入需要下载的页码,像这样"4,6,8",用逗号分开,或者中间加个减号表示范围,像这样"4-7"')
user_input = input()
if len(user_input) == 1:
start_end_ = user_input
print('需要下载的页码为:' + str(start_end_))
else:
if '-' in user_input:
test = list(user_input.split("-"))
start_end_ = list(range(int(test[0]), int(test[1]) + 1))
print('需要下载的页码为:' + str(start_end_))
else:
start_end_ = [int(n) for n in user_input.split(",")]
print('需要下载的页码为:' + str(start_end_))
return start_end_
def get_page_urls():
'''返回需要爬取的url'''
all_page_urls = []
start_end_ = get_user_input()
for num in start_end_:
all_page_urls.append('https://bing.ioliu.cn/?p={}'.format(str(num)))
return all_page_urls
def get_imges(img_list,header):
img_list = img_list.replace('640x480', '1920x1080')
img = requests.get(img_list, headers=header).content
return img
def imgs_name(html,img_number,page_number):
p = re.compile(r'[-,$()#+&*,/:]')
html_text = html.xpath("/html/body/div[3]/div[" + str(img_number) + "]/div/div[1]/h3/text()")[0]
html_text_format = re.sub(p,"",html_text)
img_name = (str(int(page_number) * 12 + img_number) + '_' + str(html_text_format) + '.jpg')
print("下载",img_name)
return img_name
if __name__ == '__main__':
header = {'User-Agent': 'w'}
page_number = 0
start_end = get_page_urls()
sleep_time = 0
for page_url in start_end:
img_number = 1
res = requests.get(page_url, headers=header).text
html = etree.HTML(res)
img_url = html.xpath('//img/@src')
if not os.path.exists('./bing_wallpaper2'):
os.makedirs('./bing_wallpaper2')
print('正在下载第{}页图片'.format(start_end[page_number]))
for img_list in img_url:
img = get_imges(img_list,header)
img_name = imgs_name(html,img_number,page_number)
with open('./bing_wallpaper2/' + img_name, 'wb') as save_img:
# 写入图片数据
save_img.write(img)
img_number += 1
time.sleep(8)
page_number += 1
