linux 的常见,常用操作,备忘吧。
目前还用不到生物云计算。
为什么生物学软件都是基于Linux操作系统?
- Linux 系统是开源免费的。
- 不需要图形界面,节约资源。
- 强大的命令行模式,适合自动化。
- 适合大规模的计算。
命令行和参数
date 就可以看时间了
cal 显示日历
who 显示以登录的用户列表
id 用户id名称
uptime 显示系统运行的时间
last 显示最近用户登录的记录
clear 清空。
find 查找
file 查看文件属性
cut 切分文件
join 连接
远程登录
PuTTY 远程登录
一般我用vscode远程登录服务器。
服务器文件传输
FileZilla 文件传输工具
ncbi ftp 网址可以登录ncbi服务器,佚名登录
Ftp Service
scp 传输命来可以实现传输。一般是用其他的传输工具。
13 display 图形查看工具
一般可以vscode远程都可以实现这些功能,不用那么复杂。
14 Linux 目录分析
可以网上找找资料
15 cd 与 ls
这种问题可以ranger 解决所以
cd - 后退命令
ls -lh
ls *.la 列出以la 结尾的文件
16 baserc 环境配置
etc 就是配置目录
.baserc 就是在开机时候执行的文件,
# 显示日期
date
# 显示一段话
echo "Hello Welcome to Linux"
# 设置命令别名
alias work = 'cd ~/workspace'grep “export” ~/.bashrc 表示在baserc中查找export这个单词。
17 chmod 权限控制
Linux 是一个多用户的系统,多任务的操作系统。
文件目录权限可分:
- 可读:用r代表reads
- 可写:w代表write
- 可执行:x代表execute
权限是十个字符
drwxr-xr-x 1 theing theing 4096 Apr 18 22:57 ./
其中第一个字符为一个单位,后面三个字符为一个单位。
l 为连接文件
d 表示是一个文件夹
- 表示为一个普通文件
chmod 命令来控制文件权限
0表示没有权限
1表示课执行权限
2表示可写权限
4表示可读权限
7:可读可写可执行 4+2+1
6:可读可写 4+2
5:可读可执行 4+1
700 属主主可读可写可执行,同用户组没有权限
755 属主可读可写可执行,同用户组只能可读可执行,组外用户只能可读可执行
644 属主可读可写,同组用户只能可读,组外用户只能可读
比如 这个文件就只能自己读写行
chmod 700 -r *.test.py同一目录下的文件修改需要用到R递归,*通配符也可以用到。
19 SuperUser
fdisk 就是format disk格式化磁盘
useradd gene 可以创建一个gene的用户
passwd gene 可以给这个用户添加密码
groupadd bioinfo 这样就可以创建一个bioifo的组
usermod -G bioinfo gene 就可以将gene 添加到bioinfo 的组中
groups gene 可以查看用户所在的组
userdel gene 可以删除用户
20 获取帮助
程序是 按照一定的预设规则来处理一定的事情。
软件指程序与其相关文档或其他从属物的集合。
软件 = 程序 + 文档
info ls
info cd 等也可以查看命令信息
man
21 Linux 文件
系统一切基于文件
修改文件后缀名,
mv K12fna k12
| 后缀 | 解释 |
|---|---|
| .asn | genome record in asn.1 format |
| .faa | protein sequences in fasta format, text file .ffn |
| .frn | rna coding portions of the genome segments .gbk |
| .gff | genome features |
| .ppt | protein table |
| .rnt | rna table |
| .rpt | summary report |
ls -ld /dev/ 可以查看文件属性
ls -lh /dev/
stat K12.fna 也可以查看文件属性
du 可以查看文件的大小个目录的大小
文件操作
主要讲了移动,重命名,复制粘贴等操作。
软连接,ln -s基本可以代替cp命令,因为连接可以节省资源,还有一种硬链接(ln),允许一个文件有多个路径,基本也是软连接,但是你删除本体的时候就会转移,永远无法真正的删除,只能将所有的文件连接删除。
谨慎使用rm命令
22 目录操作
ranger 也可以
目录和文件夹一个意思
mkdir 创建目录
可能就是一个通配符的使用上,我不是很流畅
23 文件查看
less命令可以查看文件少量的文字信息,推荐使用more可以查看文件的大量信息
less 可以读取很大的文本,因为他只是将一部分内容加载到内存中,而在windows中就必须将整个文本读取到内存中。
less 中可以用”/“来查询需要的字符,”/?”就是向上搜索。
其次还可以用cat命令来查看一个小的文本文件,小的命令脚本。
tac 与cat相反 是把文本反过来显示
head命令可以显示前面的10行,可以更改
head -20
head -n 20
显示前面的20行的文字
24换行符
head -10 linux.fasta |cat -A
可以显示10行中显示换行和回车的符号
linux 中的转换工具
dos2unix : windows 转换linux
unix2dos : linux 转换windows
unix2mac : linux 转换mac
mac2unix : mac 转换为linux
25 vim文本编辑器
vim有三种模式
命令模式,插入模式,可视化模式
在vimrc中
# 表示语法高亮
syntax on
# 显示行号
set nu
# 文本为utf-8的格式支持中文
set encoding=utf-8
# 打开光标的行列显示功能
set ruler
# 不设置备份
set nobackup
# 一个tab等于4个空格
set tabstop=426 vim 高级技巧
不过这些都可以用vscode替代。习惯用vscode扩展。
ctrl + B 往前移一页
ctrl + F 往前移一页
ctrl + U 屏幕往后移动半页
w 每次移动一个单词
6x 表示删除光标后面的6个字符
d6 删除6行
yy 表示复制
pp 表示粘贴
ctrl + r 后退
. 可以重复上一次操作
? 可以搜索要查找的内容,用N查看下一处
在编辑模式下用ctrl+P 或ctrl + N 来自动补齐
命令模式下nohl(no heaght line 高亮的意思)可以去除高亮。
:%s/human/humwoman/gc 表示全部替换human>humwoman
也可展示的将vim后台,命令模式下
:sh 可进入base ctrl + D 可回到vim中
:split 可用于分屏显示 ctrl + w可用于各个屏幕之间的切换
:vsplit 可用于纵向分屏
:onoly 只显示一个窗口
27 - 文件的压缩
zip gzip bzip2;
gzip
gzip seq.fnagzip 后面加上要压缩的文件就可以用于压缩,压缩后可用less、zcat查看gzip -b或者gunzip后面接文件就可以解压了
具体可help 查看使用信息
zip 适用于打包
zip + 打包后的文件名称.zip结尾 + 要打包的文件
具体可 –help 查看使用手册
unzip 可用于解压
bzip2 压缩效率最高
bzip2 + 要压缩的文件
bunzip2 + 要解压的文件
具体可help查看使用帮助
RAR压缩文件
用rarlinux 工具
不可以用了一个压缩工具后用其他的压缩用具继续压缩
28 文件的打包tar
tar 工具是很强大的工具,可以help查看
一般用 tar -zxvf 去解压文件
如果遇到要把文件添加到压缩文件中怎么办,不用解压后添加在压缩,
可以用-r 选项添加文件,-u可以替换文件。
29 生物软件的安装
一个生物信息软件的网站,这是一个生物信息的导航网站,
30 文件统计及其切分
文件的统计
wc + 文件名 统计
结果分别行数,字数,字节数,文件名
文件的拆分(都不是很常用)
split 和 cut 命令
split 是按照行切分数据而cut是按照列切分数据的
cut -b 1 blast_m8.list 就是将文件中每一行第一个字母输出出来。
cut -b 1-28 blast_m8.list 就是将文件中每一行1-28的字母输出出来
其中cut 可用到域这个东西, “|”,竖线中的文字代表着一个域。cut -d "|"-f 4 blast_m8.list 提取第四个域中的内容。
31 文件的比较域校验
diff和cmp来比较两个文件之间的差异
diff主要是以行为单位比较。
cmp主要是以字节为单位比较。
diff gene_v1.fa gene_v2.fa
这样就可以比较出两个文件之间的差异。
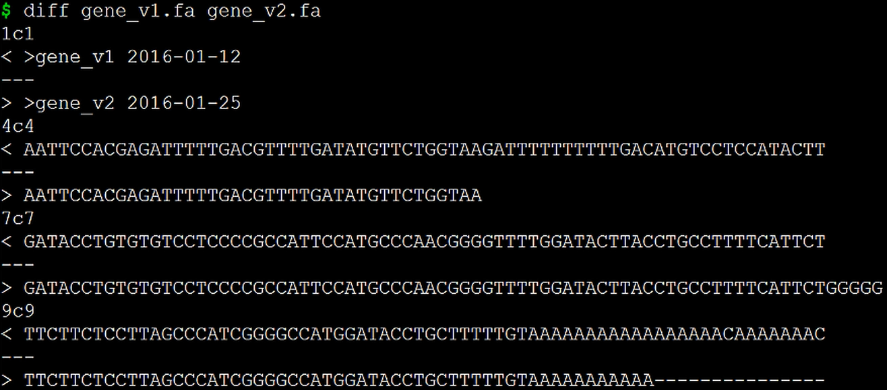
1c1表示第一个文件的第一行有变化,其他a表示增加,d表示删除
32 快捷方式
就是要使用全路径才可以在任意目录下使用命令。
系统的命令主要是放在bin和sbin下也就是/usr/bin/
方式
将程序的执行程序添加到path变量中,或者将软件的执行程序拷贝到/usr/bin或者/usr/loca/bin中
其中一个好的方法就是在程序的文件下创建一个bin目录存放所有要执行的程序软连接ln -s,然后将这个目录添加到PATH路径如
export PATH=”$PATH:/ifsl/Software/bin/:$PATH/“
33 常见问题
不断的实践操作,
34 Linux 进程管理
uptime 是系统运行的时间,
w 直接现实所有用户的信息
Linux 下每个进程的优先级是不一样的,一共40个级别
ps 和 top 可以查看进程
修改进程可以用nice 命令
进程的前后台处理
可以在要运行的程序后面加一个 “&”,这样就可以后台运行了
jobs 可显示后台运行的程序
使用fg可以把后台程序调回前台,调回前台时无法使用命令,可以使用ctrl+z将程序暂停,jobs可以显示程序的暂停情况,bg就可以后台继续运行程序
其次还要nohup 可以在用户退出时继续执行程序,继而还要weit,sleep
35 进程管理top
这个命令就相当于win中的资源管理器,win是模仿Linux加上了图形界面
东西有点多,,可以网上查找资料。
在top模式下,按K可以进入kill也就是杀死进程,输入进程的PID就可以杀死进程。
进程终止信号,
- 1 终端断线
- 2 中断,相当于Ctrl + C
- 3 退出(同Ctrl+\)
- 15 终止进程,默认为15
- 9 强制终止
- 18 继续(与STOP相反,fg/bg命令)
- 19 暂停(同Ctrl+Z)
在top中查看到PID后可以直接在终端中使用kill命令,
kill -9 30530
强制终止30530进程
36 进程管理ps命令
top是动态的,ps是静态的
ps 可显示当前的进程,不包括系统进程
ps 常用命令
ps -A 列出所有进程
ps -a 列出终端上的进程,包括其他用户的进程
ps -r 显示运行中的进程
常用的选项组和是
ps -aux | less
ps -lux | less
ps -fx 可以用竖型格式显示进程
东西太多,可以参考网上的教程,也可以help 查看文档。
pstree 可以查看进程之间的关系
pstree -a 可以查看进程的完整属性,包括路径
37 数据流的重定向
echo 在终端中输出一串信息
bc 计算器
scale = 4 表示存在四个小数,可以计算四个浮点数
quit 可以退出计算器
“>”表示数据重定向,经常用到,”>>”表示追加到文件的末尾
可用于文件的合并
cat –help >cat_help.txt
可以把显示在屏幕上的帮助信息写入到help.txt文件中。
cat seq1.fna seq2.fna >seqs.fna
这样就可以把两个文本合并在一起,但是可以用vscode远程这些东西。
问题,
当一个管道被占用,输出不了信息。可以大于前面添加一个2也就是另一个管道。
cat -2 2>>error.txt
38 命令协作管道
基本理解可以用蓄水池的出口用另一个管子另外接一个管子使改变流出方向,进行另外的处理。
例子:
echo “123456789”|wc
结果使10个其中包含了换行符,其实是9个字符
echo -n “123456789”|wc -m
-n 表示 去除结尾的换行符,-m 表示只统计字符
例:
ls -a *.fna | wc -l
就可以统计目录下以.fna 结尾的文件
其中的管道在实际运用中可以大量使用到,要即使查看资料
39 文本排序sort
排序情况:
- 根据数字大小进行排序;
- 根据字符大小排序;
- 根据文件指定的顺序进行排序。
sort 默认是从首字母从大到小排序。
sort -n
根据数字大小排序
-r 相反的顺序排序,具体可以–help
40 文件搜索
which 查找命令
locate 可以查找所有相关的文件,基本就是模糊查找
find 一般不要在根目录下操作
41 文本筛选grep
- find 搜索目录下满足条件的文件;
- grep 搜索文件内满足条件的内容行;全称是 全局正则表达式版本。
grep 的使用
有时要看–help 参考一些别人写的常用功能。
如:
grep ">" gene.ffn |wc表示在gene.ffn这个文件中搜索”>” 输入管道”|”用wc统计,一般可用于fasta这种基因序列,一条序列都是”>”符号开头的。
ls
42 正则表达式
要想真正发挥grep的功能必须要掌握正则表达式的功能,正则表达式也适用于其他语言
grep “eat” 001.txt
就会把文本中所以含有eat 的行显示出来。这个时候就会用到正则表达式。
grep “^eat” 001.txt 就只能搜索到以eat开头的词。
grep “eat&” 001.txt 就只能搜索到以eat结尾的词。
grep “\beat\b” 001.txt \b为单词锚定符,这样就只能匹配到eat的词组。
正则中的符号表示
. 任何单个字符的通配符。
\ 表示转义符,比如:. 表示“.”
- 通配符,是多个字符的通配符
grep "go.*gle" 001.txt能匹配所有以go开头以gle结尾的词组。? 表示{0,1},0或者1次
- 表示{1,},一次以上
- 表示{0,},0到无穷大
grep -E "go{1,8}gle" 001.txt表示能匹配1-8个字符grep "\(google\)" 001.txt表示已google为一个字符进行匹配。| 表示或,比如
grep -E "beat|seat|heat|feat" 001.txt表示如果符合其中一个就可以匹配[] 表示一个字符集列表,如
grep [bfhs]eat 001.txt就可以从[]中符合的字符中进行匹配。只匹配单个字符。[a-z]匹配所有小字母;[A-Z]匹配所有大写的字母;[0-9]表示匹配所有数字。\w单词,[A-Za-z0-9],单词包括字母,数字和下划线。
\s空白,是字符集换页、制表、换行、回车以及空格[\f\t\n\r] 的简写;
\d 匹配所有数字[0-9].
\W 表示非字符
\D 表示非数字
\S 非空白字符
sed–波流(一)
强大是文本编辑工具,sed & awk
- sed 全称是Stream EDitor ,是一种流编辑器。相当于一个磨具,能对数据进行增删改查等操作,形成固定的格式。
- sed 一次处理一行,处理存于一个模式缓存空间
sed -e 's/GI/gi/g' seq.fna, 其中-e一般可以不写,s表示一种模式,为替换模式,寻找GI替换为gi,g表示globe全局搜索替换,默认是只替换一次,所以都加上g。也可以写数字,表示替换几次
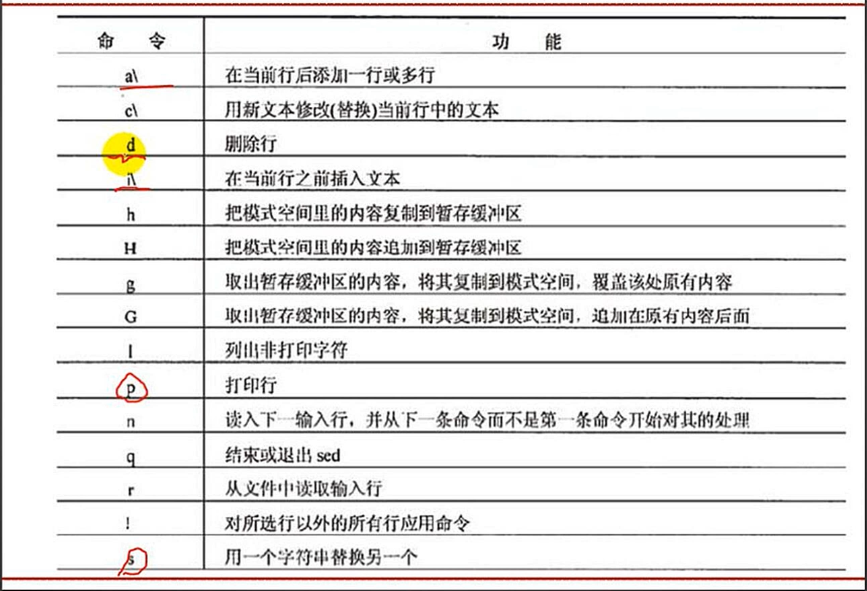
sed -e '/^\s*$/d' seq_with_space.fna,正则中表示一个空白行,d表示删除。这样就可以删除所有空白的行。- `sed -n ‘1307p’ seq.fna 表示输出1307行的内容。

