喜欢一件事就去争取吧。
1. 课程介绍
2. 数据分析
数据就是事物进行记录可鉴别的符号,是对客观事物性质状态以及相互关系等进行记载的物理符号。
数据分析过程:
- 数据的采集
- 数据的存储
- 数据统计:使用统计方法,有目的的对收集的数据进行分析处理,并解读分析结果。结绳、算盘、计算器、excel
- 数据挖掘:一般是指从大量的数据中通过算法搜索隐藏于其中的信息的过程。挖掘是一个探索的过程,统计是有目的的。
- 数据的可视化
- 进行决策,利用统计结果进行有目的的决策
3. 数据挖掘
介绍了数据挖掘的重要性。
4. 数据可视化
人是视觉动物
5. R语言介绍
- 有效的数据处理和保存机制。
- 拥有一整套数组和矩阵的操作运算符
- 一系列连贯而又完整的数据分析中间工具
- 图形统计可以对数据直接进行分析和显示,可用于多种图形设备
- 一种相当完善、简介和搞笑的程序设计语言
- R语言是彻底的面向对象的统计编程语言
- R语言和其他变成语言、数据库之有很好的接口
- R语言是自由 的软件,功能不比任何其他同列软件差
- R语言的网上资源丰富
Rebolutions R 已经被微软收购了,该命为Microsoft R
6. R应用的案例
一个维生素C与牙齿生长的关系
在官网上面下载R语言的安装包,
7. R语言的安装
不着急,这个在网络上有大量的资源
8. R 运行与设置
讲述了R自带的GUI
9. Rstudio
一般都是用到了这个软件, 介绍了各种界面的操作。
10 基本操作
设定工作目录,查看工作目录
getwd()
设置工作目录,填入你的工作目录
setwd(dir = “”)
列出每个变量的所有信息
ls.str()
11. R扩展包
查看扩展包的位置
.libPaths()
查看安装了哪些安装包
library()
一次安装多个包
install.packages(c(“AER”,”ca”,””)
12 R包的使用
R软件包的组成
- base
- datasets 存放R内置的数据集
- utils R语言的工具函数
- grDevices 基于base 和greph的图形设备,与绘图相关的函数都在这个包里
- graphics 基于base图形的R默认的绘图函数都在这个包里
- stats 存放与统计相关的函数,
- methods R对象一般的定义方法和类
- splines 基础包
- stats4 基础包
- tcltk 基础包
广州,兰州,的镜像是可以用的,兰州是比较快的.
加载包
require(vcd)
移除加载
detach(“package:vcd”)
删除包
remove.package(“vcd”)
查看以安装的包
installed.packages()
查看工具包的帮助信息
help(package=”vcd”)
也可以用library来查看帮助信息
library(help=”vcd”)
列出vcd中所有包含的函数
ls(“package:vcd”)
列出vcd中所有的数据集
data(package=”vcd”)
R包的批量移植
一种方案:
Rpackage <- installed.packages()[,1]
save(Rpackage,file=”Rpack.Rdata)
列出安装包的第一列,导出到一个文本中,在另一个电脑上load加载到一个变量中,
for (i in Rpack) install.packages(i)
这样就可以批量安装包了.
13 获取帮助
比如help()会在浏览器中打开帮助信息,和?sum一个意思
help(sum)
?(sum)
快速了解函数的参数,而不想去看文档args函数
args(plot)
还可以用esample 函数去示例一个函数的使用
example(hist)
也可以用demo 这种示例
demo(graphic)
用help查看包的帮助,这个是在网上查看帮助信息
help(package=vcd)
用vignette()函数,这个一些库可能没有这个文档,
vignette(“vcd”)
??qplot
网络搜索相关的函数
RSiteSearch(“matlab”)
rseek.org 是一个与R相关的论坛
14 excel 案例
主要是excel 数据透视表的使用案例,没有数据不是很懂,老师也说了,excel也是一种很强大的数据分析工具,也可以学习excel的使用
15 内置数据集
R内置了很多的数据集,存在于datasets这个包中
直接data()就可以列出很多的数据集,rivers可以列出北美141条河流的长度
可以用help("mtcars")这样的去查看数据的帮助信息
加载数据集
data(package=”MASS”)
这样只是加载数据集,而包就不用加载进来
data(Chile,Package=”car”)
16 数据结构
数据结构式计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素集合。
这个是很重要的,知道是什么,知道为什么。
R中数据类型
- 数值型,数值可以用于直接计算。
- 字符串型,可以进行连接,转换,提取等。
- 逻辑型,真假。
- 日期型等。
这个跟Python差不多。
普通的数据结构:向量,标量,列表,数组,多维数组。
特殊数据结构:perl中的哈希,python中的字典,c语言中的指针等。
R对象:object, 他是指可以赋值给变量的任何事物,包括常量,数据结构,函数,甚至图形。对象都拥有某种模式,描述了此对象是如何存储的,以及某个类。
17 向量
向量,vector, 是R中最重要的一个概念,它是构成其他数据结构的基础,R中的向量概念和数学中的向量是不同的,类似于数学上的集合,有一个或多个元素所构成。向量其实是用于存储数值型,字符型或逻辑型数据的一维数组。
R中用函数 “c ”来创建向量。如:
c <- c(1,2,3,4)
z <- c(TRUE,T,F)
R中 euro,rivers,state.abb,state.area都是向量的数据结构。
等差数列,输出1到100的等差数列
c(1:100)
输出步长为2的等差数列
seq (from=1,to=100,by=2)
输出重复序列,x重复5次
rep (“x”,5)
rep (x,5)
可以用each来控制一个元素的重复次数。如下可以吧x中的元素重复5次,times可以把整数组重复2次。
rep(x,each=5,times=2)
如何查看数据类型,
mode(z)
R中向量化编程
x <- c(1,2,3,4,5)
y <- c(6,7,8,9,10)
x*2+y
8 11 14 17 20
在x中取出x>3的值
x[x>3]
使用rep来控制每个元素的出现次数
rep(x,c(2,4,6,1,3))
输出[1] 1 1 2 2 2 2 3 3 3 3 3 3 4 5 5 5
18 向量索引
在R中元素的第一个值是从 “1” 开始,不是0length(x)可以算出元素的个数。
如:x为1-100的元组
x[c(1,23,55,32,78)]
[1] 1 23 54 65 输出
重要使用逻辑向量的值来进行向量的索引。比如:
y <- c(1:10)
y[c(T,F,T,F,T,F,T,T,T,T,T)]
[1] 1 3 5 7 8 9 10 NA 输出为真的数字 NA为缺失值
又比如
z <- c(“one”,”two”, “three”, “four”, “five”)
z
[1] “one” “two” “three” “four” “five”
z %in% c(“one”,”two”) 判断是否在z中有这个字符。
[1] TRUE TRUE FALSE FALSE FALSE
使用元素名称进行访问,相当于字典中的键值对
> y <- c(1:6)
> names(y) = c("noe", "two", "three", "four", "five", "six")
> y
noe two three four five six
1 2 3 4 5 6
> names(y)
[1] "noe" "two" "three" "four" "five" "six"
> y["two"]
two
2 append函数,可以指定在那个位置进行插值。
> x <- c(1:100)
> v <- c(1:3)
> v[15] <- 15
> v
[1] 1 2 3 NA NA NA NA NA NA NA NA NA NA NA 15
> append(x = v, values = 50,after = 12)
[1] 1 2 3 NA NA NA NA NA NA NA NA NA 50 NA NA 15
>删除向量可以用rm()函数,也可以在索引中加负号,但只是暂时的,但是可以传回原来的值
> rm(y)
> y <- c(1:10)
> y[-c(1:3)]
[1] 4 5 6 7 8 9 10
> y <- y[-c(1:3)]
> y
[1] 4 5 6 7 8 9 10
19 向量的运算
“**”为幂运算
“%%”求余运算
“%/%”为整除运算
两个元素的相加必须是相同的元素个数。python中这个还是很好解决的
> x = c(1,2,3)
> y = c(1,2,4,5,6)
> x>y
[1] FALSE FALSE FALSE FALSE FALSE
Warning message:
In x > y : 长的对象长度不是短的对象长度的整倍数
> c(1,2,3) %in% c(1,2,4,5,6)
[1] TRUE TRUE FALSE其他的函数运算
> abs(-6) 为绝对值
[1] 6
> sqrt(25) 开方
[1] 5
> log(16,base=2)
[1] 4
> log2(16) 对数函数
[1] 4
> ceiling(c(-2.3,3.1415)) 返回整数部分
[1] -2 4
> sin(x) 三角函数
[1] 0.8414710 0.9092974 0.1411200
> vec = 1:100
> sum(vec) 求和函数
[1] 5050
> range(vec) 范围,最大值和最小值
[1] 1 100
> max(vec) 最大值
[1] 100
> min(vec) 最小值
[1] 1
> mean(vec) 均值
[1] 50.5
> var(vec) 方差
[1] 841.6667
> sd(vec) 标准差
[1] 29.01149
> median(vec) 中位数
[1] 50.5
> round(var(vec),digits = 2) round默认是整数digits设置小数位数
[1] 841.67
> prod(vec) 各元素连续乘积
[1] 9.332622e+157
> quantile(vec,c(0.5,0.4,0.8)) 分位数
50% 40% 80%
50.5 40.6 80.2寻找元素位置which,返回索引
> t = c(1,5,4,7,2,9,6)
> which.max(t)
[1] 6
> which(t==7)
[1] 420 矩阵与数组
矩阵式一个按照长方阵列排列的复数或实数集合.向量是一维的,而矩阵式二维的,需要有行列.基本就跟excel中的数据表差不多.
内置矩阵数据集
> iris3
> state.x77
> heatmap(state.x77) 热图用matrix()创建矩阵
> m = matrix(1:20,4,5) 1到20,4行5列的矩阵
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> m = matrix(1:20,4,5,byrow = T/F) 通过行或列更改行列名称
> rname = c("1","2","3","4")
> cname = c("1","2","3","4","5")
> dimnames(m) = list(rname,cname)
> m
1 2 3 4 5
1 1 5 9 13 17
2 2 6 10 14 18
3 3 7 11 15 19
4 4 8 12 16 20dim()向量设定函数
设定为一个2行2列的3高的三维数组
> x = c(1:12)
> x
[1] 1 2 3 4 5 6 7 8 9 10 11 12
> dim(x)
NULL
> dim(x) = c(2,2,3)
> x
, , 1
[,1] [,2]
[1,] 1 3
[2,] 2 4
, , 2
[,1] [,2]
[1,] 5 7
[2,] 6 8
, , 3
[,1] [,2]
[1,] 9 11
[2,] 10 12如何访问二维数组的值
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> m[2,2] 二行二列
[1] 6
> m[2,] 二行
[1] 2 6 10 14 18
> m[,2] 二列
[1] 5 6 7 8
> m[-1,2] "-"为去除第一列
[1] 6 7 8
> m+1 每个元素加一
[,1] [,2] [,3] [,4] [,5]
[1,] 2 6 10 14 18
[2,] 3 7 11 15 19
[3,] 4 8 12 16 20
[4,] 5 9 13 17 21行列的计算
> colSums(m) 计算每一列的和
[1] 10 26 42 58 74
> rowSums(m) 计算每一行的和
[1] 45 50 55 60
> colMeans(m) 列的平均值
[1] 2.5 6.5 10.5 14.5 18.5
> rowMeans(m) 行的平均值
[1] 9 10 11 12矩阵的内外积
> n = matrix(1:9,3,3)
> t = matrix(2:10,3,3)
> n
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> t
[,1] [,2] [,3]
[1,] 2 5 8
[2,] 3 6 9
[3,] 4 7 10
> n*t 内积
[,1] [,2] [,3]
[1,] 2 20 56
[2,] 6 30 72
[3,] 12 42 90
> n %*% t 外积
[,1] [,2] [,3]
[1,] 42 78 114
[2,] 51 96 141
[3,] 60 114 168其他
> diag(n) 对角线
[1] 1 5 9
> diag(t)
[1] 2 6 10
> m
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
> t(m) 行列转换
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 2021-列表
列表顾名思义就是用来存储很多内容的集合,列表和数组基本是等同的,但是在R中,列表是最复杂的一种数据结构,也是非常重要的一种数据结构.
列表中可以存储若干个向量,矩阵,数据框,甚至其他的列表组合.
向量只能存储一种数据类型,列表却可以存储多种数据类型.
比如: 其实跟Python中的list是一样的
> a = 1:20
> b = matrix(1:20,4)
> c = mtcars
> d = "This is a test list"
> mlist = list(a,b,c,d)
> mlist
[[1]]
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[[2]]
[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20
[[3]]
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
[[4]]
[1] "This is a test list"mlist[[1]] 访问的数据本身,如果是一个中括号,则数据类型是一个list.所以给列表赋值的时候要两个中括号.
> mlist[[5]] = iris
> mlist[-5] 就可以删除这个索引的值22 数据框
数据框是一种表格式的数据结构,
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量.不同的行业对于数据集的行列叫法不同.
数据框实际上是一个列表.列表中的元素就是向量,这些向量构成数据框的列,每一列的长度相同,数据框的列是必须命名的.
比如excel中的数据表就是一个数据框,其中的每一列的元素格式可以不同.
矩阵的数据必须是一个类型,数据框可以不同,数据框的每一列必须是同一类型,每一行可以不同.
生成数据框
state = data.frame(state.name,state.abb,state.region,state.x77)数据框的访问,基本是一样的
> state[1] 输出第一列
> state[c(2,4)] 输出2和4列
> state[,"state.abb"]
> state$state.abb 采用$符号的方式访问与plot函数使用的实例,绘制women的身高体重散点图
plot(women$height,women$weight) 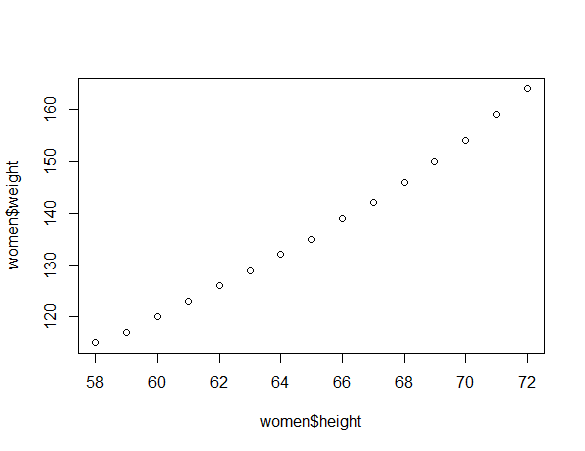
不使用$符号的各种操作
attach加载与detach取消加载;可以在终端中直接敲数据框的名字就可以了,就可以摆脱$符号
> attach(mtcars)
> mpg 数据框的名称
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4
[16] 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7
[31] 15.0 21.4with函数,不过要一个一个的加载,一般还是推荐使用$符号
> with(mtcars,{hp})
> hp
[1] 110 110 93 110 175 105 245 62 95 123 123 180 180 180 205 215 230 66 52
[20] 65 97 150 150 245 175 66 91 113 264 175 335 109关于单双括号的解释,就像使火车,单括号还是访问的火车中的车厢,双括号就相当于把车厢取出来单独使用.
23 因子
R中的因子使不好理解的
变量的分类
- 名义型变量:一般为字符串
- 有序型变量
- 连续型变量:一般为数值型
在R中名义型变量和有序型变量称为因子,factor. 这些分类变量的可能值称为一个水平,level,例如good,better,best,都称为一个level. 有这些水平值构成的向量就称为因子.
因子的应用
- 计算频数
- 独立性检验
- 相关性检验
- 方差分析
- 主成分分析
- 因子分析等
table频数统计.cyl就是一个因子,4,6,8就是水平
> mtcars$cyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
> table(cyl)
cyl
4 6 8
11 7 14 factor 函数可以将向量函数转换成因子,按照顺序排列
> week = factor(c("Mon","Fri","Tuh","Wed","Mon","Fri","Sun"),ordered = T,levels = c("Mon","Tue","Wed","Thu","Fri","Sat","Sun"))
> week
[1] Mon Fri <NA> Wed Mon Fri Sun
Levels: Mon < Tue < Wed < Thu < Fri < Sat < Sun
水平
> fcyl = factor(mtcars$cyl)
> fcyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8
[32] 4
Levels: 4 6 8通过水平绘制柱状图,可以很好的进行频数统计
> fcyl = factor(mtcars$cyl)
> fcyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8
[32] 4
Levels: 4 6 8
> plot(fcyl )
> num = 1:100
> cut(num,c(seq(0,100,10)))
[1] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (0,10] (10,20] (10,20] (10,20] (10,20] (10,20]
[16] (10,20] (10,20] (10,20] (10,20] (10,20] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30] (20,30]
...state.divsion和state.region,也是factor的内置数据
24-缺失数据
缺失数据可分为
- 完全随机缺失
- 随机缺失
- 非随机缺失
缺失可能是设备故障,测量的问题导致的
NA表示缺失not available的简称,不是没有值,知识未知的数值.
统计的时候跳过缺失值,但是平均值的时候还是按照全部的值的个数计算的.
> a = c(NA,1:49)
> sum(a)
[1] NA
> sum(a,na.rm = TRUE)
[1] 1225
> mean(a,na.rm = TRUE)
[1] 25用na.omit()去除缺失值
> c = c(NA,1:20,NA,NA)
> c
[1] NA 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[22] NA NA
> d = na.omit(c)
> d
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
attr(,"na.action")
[1] 1 22 23
attr(,"class")
[1] "omit"其他缺失数据
- 缺失数据NaN,代表不可能的值;
- Inf表示无穷,分为正无穷Inf和负无穷Inf,代表无穷大或者无穷小.
- Inf存在,是无穷大后者无穷小,但是表示不可能的值.
- 可以用
is.nan()来识别不可能值 - 可以用
is.infinite()来识别无穷值
25-字符串
R中可用的正则表达式
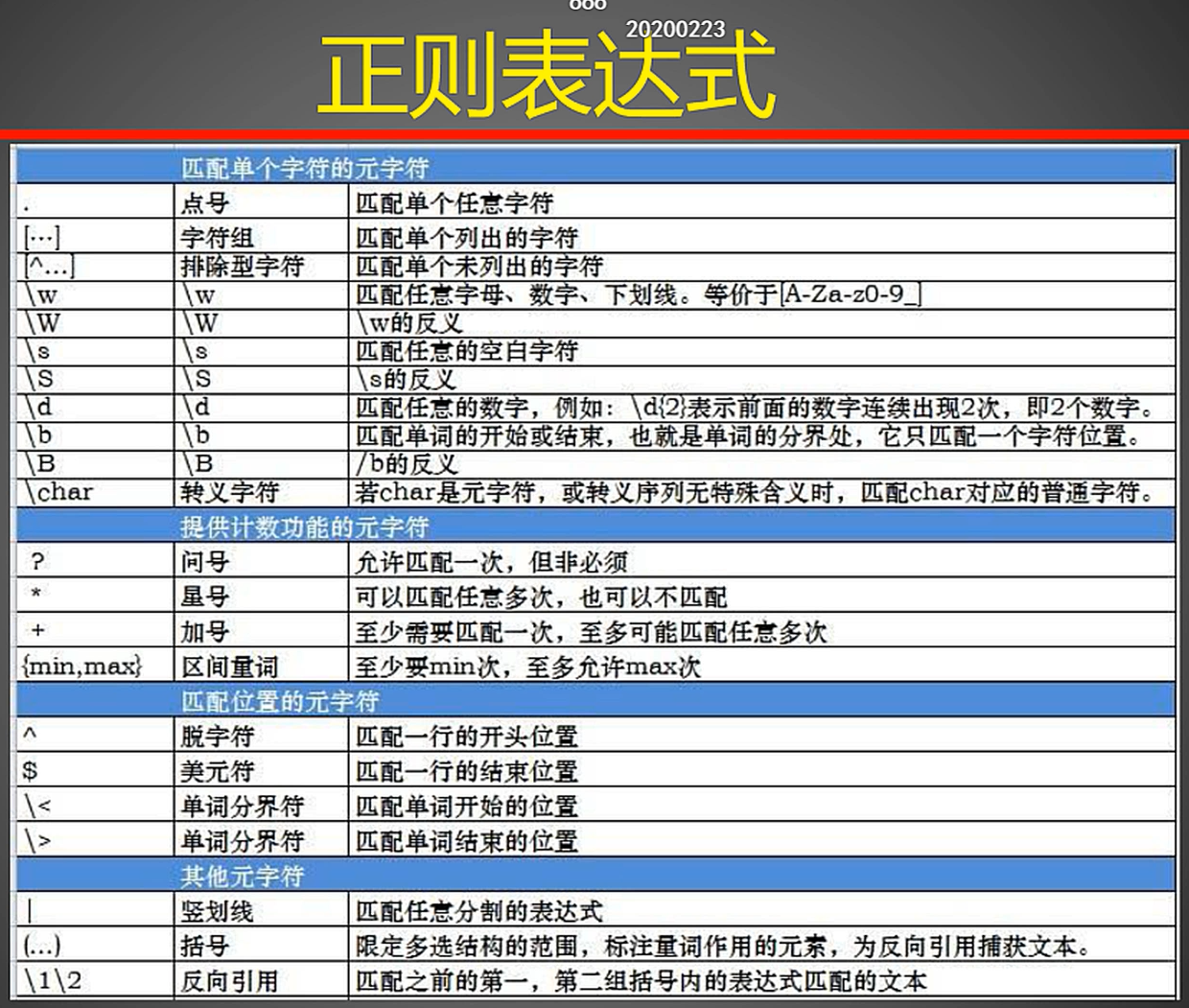
统计字符串的长度,包括字符串
> nchar("hello world")
[1] 11
> nchar(month.name) ## 可以返回向量的每个元素的长度,length不可以
[1] 7 8 5 5 3 4 4 6 9 7 8 8
> length(month.name)
[1] 12paste()可以把字符串相连
### paste() 后面的参数都会与变量的每个元素连接
> name = c("Moe","Larry","Curly")
> paste(name,"loves stats")
[1] "Moe loves stats" "Larry loves stats" "Curly loves stats"用substr()提取字符,可以提取每一个元素的字符
### start 表示起始位置,stop表示终止位置
> substr(x = month.name,start = 1,stop = 3)
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct"
[11] "Nov" "Dec"大小写tolower()和toupper()和首字母大写
> temp = substr(x = month.name,start = 1,stop = 3)
> temp
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct"
[11] "Nov" "Dec"
> tolower(temp)
[1] "jan" "feb" "mar" "apr" "may" "jun" "jul" "aug" "sep" "oct"
[11] "nov" "dec"
> toupper(temp)
[1] "JAN" "FEB" "MAR" "APR" "MAY" "JUN" "JUL" "AUG" "SEP" "OCT"
[11] "NOV" "DEC"
### 首字母大写不是很好解决,可以用正则替换,perl = T表示支持perl语言的正则表达式
> gsub("^(\\w)","\\L\\1",tolower(temp),perl = T)
[1] "jan" "feb" "mar" "apr" "may" "jun" "jul" "aug" "sep" "oct"
[11] "nov" "dec"
> gsub("^(\\w)","\\U\\1",tolower(temp),perl = T)
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct"
[11] "Nov" "Dec"grep()可以用来搜索字符串,其次还有match()
> x = c("b","A+","AC")
> grep("b",x,fixed = T)
[1] 1strsplit()可以用来分割字符串,返回一个列表,跟Python一个意思
> path = "/usr/local/bin/R"
> strsplit(path,"/")
[[1]]
[1] "" "usr" "local" "bin" "R" 后语:正则表达式是很重要的技能
附赠技能:随机字符串,比如生成一副扑克牌
> face = 1:13
> suit = c("spades","clubs","hearts","diamonds")
### FUN表示接一个函数,这里是连接函数,sep表示连接符号
> outer(suit,face,FUN = paste,sep="-")
[,1] [,2] [,3] [,4]
[1,] "spades-1" "spades-2" "spades-3" "spades-4"
[2,] "clubs-1" "clubs-2" "clubs-3" "clubs-4"
[3,] "hearts-1" "hearts-2" "hearts-3" "hearts-4"
[4,] "diamonds-1" "diamonds-2" "diamonds-3" "diamonds-4"
[,5] [,6] [,7] [,8]
[1,] "spades-5" "spades-6" "spades-7" "spades-8"
[2,] "clubs-5" "clubs-6" "clubs-7" "clubs-8"
[3,] "hearts-5" "hearts-6" "hearts-7" "hearts-8"
[4,] "diamonds-5" "diamonds-6" "diamonds-7" "diamonds-8"
[,9] [,10] [,11] [,12]
[1,] "spades-9" "spades-10" "spades-11" "spades-12"
[2,] "clubs-9" "clubs-10" "clubs-11" "clubs-12"
[3,] "hearts-9" "hearts-10" "hearts-11" "hearts-12"
[4,] "diamonds-9" "diamonds-10" "diamonds-11" "diamonds-12"
[,13]
[1,] "spades-13"
[2,] "clubs-13"
[3,] "hearts-13"
[4,] "diamonds-13"26-日期和时间
主要两点:
- 对时间序列的描述;一段时间内发生了什么.
- 利用前面的结果预测,预测接下来要发生什么.
R包的分类中Task Views有很多的处理时间分析的包
airmiles内置数据集就是一个专门的Time Series:的时间数据集.
Sys.Date()可以显示现在的时间
格式化日期类型
> a = "2017-01-01" ## 这是一个字符串类型
> as.Date(a,format = "%Y-%m-%d")
[1] "2017-01-01"
> class(as.Date(a,format = "%Y-%m-%d"))
[1] "Date" ## 这是一个日期类型更多格式化日期的参数可以查看?strftime
可以用seq()创建一个连续的时间序列,创建连续的时间点:
> seq(as.Date("2017-01-01"),as.Date("2017-07-05"),by=5)
[1] "2017-01-01" "2017-01-06" "2017-01-11"
[4] "2017-01-16" "2017-01-21" "2017-01-26"
[7] "2017-01-31" "2017-02-05" "2017-02-10"
[10] "2017-02-15" "2017-02-20" "2017-02-25"
[13] "2017-03-02" "2017-03-07" "2017-03-12"
[16] "2017-03-17" "2017-03-22" "2017-03-27"
[19] "2017-04-01" "2017-04-06" "2017-04-11"
[22] "2017-04-16" "2017-04-21" "2017-04-26"
[25] "2017-05-01" "2017-05-06" "2017-05-11"
[28] "2017-05-16" "2017-05-21" "2017-05-26"
[31] "2017-05-31" "2017-06-05" "2017-06-10"
[34] "2017-06-15" "2017-06-20" "2017-06-25"
[37] "2017-06-30" "2017-07-05"随机生成48个数字
介绍了ts函数
27-常见错误
问题:
- 等号问题,复制操作,
==表示判断是否相等 - 赋值问题
- c函数问题
- 括号的问题
- 引号问题,引号内的一边为字符
- 安装包的时候要加引号
install.packages("gclus") - 逗号问题,起一个分割作用
- 在windows中路径
/为R中的转义符 - 包是需要载入的,
- R中严格区分大小写
解决问题方法
- Rblogger
- quickR
- stackoverflow等
28-获取数据
获取途径:
- 利用键盘来输入数据;
- 读取存储在外部的数据;
- 通过访问数据框系统来获取数据;
前面的都不主流,主要是访问外部的文件,或者数据框的信息
通过ODBC 访问数据库,相当于数据库的一个驱动.install.packages("RODBC")就可以安装了,但是我这里报错了
这里讲的不是很详细
29-读取文件(一)
R几乎可以读取所有的数据文件
setwd(dir)来设置工作目录;
在工作目录下x = read.table("input.txt")就可以读取文件了,这里只是读取到内存中.
> x = read.table("c:/Users/theing/Desktop/input.txt") ## 这样也可以读取文件信息
> head(x) ## 显示头部的信息
> tail(x,n=10) ## 显示尾部的10行信息
> x = read.table("input.csv",sep=",") ## 可以读取以","分割的csv文件
> x = read.csv("input.csv") ## 这个一样的效果read.table()的参数
- skip=5 可以跳过前面的行,从第六行读取数据
- nrows=100 这样可以只读取前面100行.可以和skip 配合使用
- na.strings 处理缺失值,
- stringsAsFactors=False 用来控制字符串是否转换成因子,R会默认的将字符串转换成因子.所以要设置成false
30-读取文件(二)
read.table 也可以读取网络连接
老师展示了很多被墙了的链接,估计也是在暗示着什么
其次还介绍了foreign包,
如何搜索R的相关包
> RSiteSearch("Matlab")
檢索查詢疑問已被提交给http://search.r-project.org
计算结果应很快就在瀏覽器里打开读取剪切板的内容,
## 比如你在excel中复制了一部分内容,就可以用这个功能
## readCliboard() 就是读取剪切板的内容.
> x = read.table("clipboard",header = T,sep="\t")读取一个压缩文本的文件,R也是可以直接读取的
> read.table(gzfile("input.txt.gz")如果遇到不标准的文件格式,可以用readlines和scan
## 可以限制读入的行数
> readLines("input.csv",n=15)
> ?scan可以查看帮助31-写入文件
基本就是使用write函数
> write(x,file = "x.txt")可以用,基本和Python类似。
## sep 表示分隔符,row.name 表示行号
> write.table(x,file = "c:/sld/sdl/x.csv",sep = ",",row.name = FALSE)直接写成压缩文件,比如
> write.table(mtcars,gzfile("newfile.txt.gz")32-读取excel文件
excel也是一个很好的数据统计文件,大多时候别人都是excel,所以还是应该掌握处理excel的能力.
excel倒过来的时候用的csv格式
XLConnect包,excel包含工作簿和工作表,称为workbook,可以直接打开xlsx的文件, 注意这个包是需要安装java环境.个人觉得这个没必要,能用excel处理就用excel处理.
> ex = loadWorkbook("data.xlsx")
> readWorksheet(ex,1) ## 1表示查看的第一个工作表
> ?readWorksheet ##查看具体的功能介绍编辑excel
分四步法
- 用loadWorkbook创建一个工作簿
- 工作簿中创建工作表
- 用writeWorksheet工具把数据保存到工作表中
- 用seveWorkbook保存为excel文件
查看XLConnet的详细介绍> wb = loadWorkbook("file.xlsx",create = T) > createSheet(wb,"Sheet 1") > wtiteWorksheet(wb,data=mtcars,sheet = "Sheet1") > seveWorkbook(wb)vignette("XLConnect")
xlsx包的使用
## 读取第一个工作表的1到100行的内容,sheetName指明工作表的名称.append是否追加写入(新的文件,还是更改表格).
> library(xlsx)
> read.xlsx("data.xlsx",1,startRow = 1,endRow = 100)
> write.xlsx(x,file = "rdata.xlsx",sheetName = "Sheet 1",append = F)33-读写R格式的文档
R有两种格式的文件,Rdata和RDS
RDS文件
> saveRDS(iris,file="iris.RDS")
> readRDS("iris.RDS")Rdata 文件,项目文件,使用load()加载,一般双击就可以打开了.
## 示例
> load(".RData")
> save(iris,iris3,file = "c:/Users/theing/Desktop/iris.Rdata")保存镜像
save.image()34-数据转换
数据的收集和存储已经会了,这里开始数据的转换,转换后就可以分析数据了.
前面介绍是向量,矩阵,数组,数据框,列表,因子,时间序列,等的增删改查
> cars32 = read.csv("mtcars.csv")
> is.data.frame(cars32)
[1] TRUE ## 表示是一个矩阵
> is.data.frame(state.x77)
[1] FALSE转换为数据框
> dstate.x77 = as.data.frame(state.x77)转换为矩阵,变为字符串类型的矩阵
> as.matrix(data.frame(state.region,state.x77))methods查看内容
> methods(is)
> methods(as)向量是R种基本的数据类型,加上一个维度就是数组或者矩阵
## > is.data.frame(state.x77)
[1] FALSE
> x = state.abb
> dim(x) = c(5,10)
## 向量变因子
> x = state.babb
> as.factor(x)
## 变为列表
> as.list(x)添加一个数据框
> state = data.frame(x,state.region,state.x77)35-数据转换(二)
讲一个取子集的操作
## 这是一个数据框
> who = read.csv("WHO.csv",header = T)
> who1 = who[c(1:50),c(1:10)]
> who2 = who[c(1,3,5,8),c(2,14,16)]取出CountryID 在50到100的国家,似乎不知道怎么去理解
> who4 = who[which,(who$CountryID > 50 & who$CountryID <=100)]
> who4 = subset(who,who$CountryID > 50 & who$CountryID <=100)sample抽样,机器学习中抽取两份样本,一份用来建模,一份用来验证模型的有效性
> ?sample
## 例子,第一个参数为是选择那个向量,第二个是要抽取的个数,replace 表示是否放回式的抽样.
> x = 1:100
> sample(x,30,replace = T)
[1] 39 23 11 26 50 86 86 71 26 6 10 93 81 73 74 87 98
[18] 6 17 87 10 69 51 24 22 70 33 68 97 82
> sort(sample(x,30,replace = T))
[1] 8 19 23 23 28 31 32 40 40 42 50 50 50 51 52 55 58
[18] 60 63 70 73 77 78 83 83 84 85 89 93 96sample对数据框进行抽样,取子集
> who[sample(who$CountryID,30,replace = F),]删除固定行的数据
## 注意逗号的位置
> mtcars[-1:-5,]
## 清空这一行的数据
> mtcars$mpg = NULL 如果遇到几个数据表进行汇总,这里要用到数据框的合并,可以使用cbind和rbind函数,cbind添加一列,rbind添加一行.
cbind合并列
## USArrests是一个数据集,state.division是一个因子
> cbind(USArrests,state.division)rbind合并行,这个比较麻烦,需要所有的列有源数据集有相同的列名
## 取出前20行和尾20行合并
> data1 = head(USArrests,20)
> data2 = head(USArrests,20)
> b = rbind(data1,data2)cbind和rbind也可以用于矩阵
回顾rownames可以取出行名
判断向量和数据框中哪些是重复值
> duplicated(who)用unique(data4)可以一步取出重复项
36-收据转换(三)
R中行列的调换,excel中可以复制后选择性粘贴.R中可以用t()函数实现转换
> sractm = t(mtcars)单独一行的反转,生物序列中很常见,主要是反向互补,可以使用rev函,reverse的意思
> letters
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l"
[13] "m" "n" "o" "p" "q" "r" "s" "t" "u" "v" "w" "x"
[25] "y" "z"
> rev(letters)
[1] "z" "y" "x" "w" "v" "u" "t" "s" "r" "q" "p" "o"
[13] "n" "m" "l" "k" "j" "i" "h" "g" "f" "e" "d" "c"
[25] "b" "a"数据框中的数据反转,思路就是,提取行名,反转,以反转后的行名为索引
> rowname(women)

