喜欢一件事就去争取吧。
34-数据转换
数据的收集和存储已经会了,这里开始数据的转换,转换后就可以分析数据了.
前面介绍是向量,矩阵,数组,数据框,列表,因子,时间序列,等的增删改查
> cars32 = read.csv("mtcars.csv")
> is.data.frame(cars32)
[1] TRUE ## 表示是一个矩阵
> is.data.frame(state.x77)
[1] FALSE转换为数据框
> dstate.x77 = as.data.frame(state.x77)转换为矩阵,变为字符串类型的矩阵
> as.matrix(data.frame(state.region,state.x77))methods查看内容
> methods(is)
> methods(as)向量是R种基本的数据类型,加上一个维度就是数组或者矩阵
## > is.data.frame(state.x77)
[1] FALSE
> x = state.abb
> dim(x) = c(5,10)
## 向量变因子
> x = state.babb
> as.factor(x)
## 变为列表
> as.list(x)添加一个数据框
> state = data.frame(x,state.region,state.x77)35-数据转换(二)
讲一个取子集的操作
## 这是一个数据框
> who = read.csv("WHO.csv",header = T)
> who1 = who[c(1:50),c(1:10)]
> who2 = who[c(1,3,5,8),c(2,14,16)]取出CountryID 在50到100的国家,似乎不知道怎么去理解
> who4 = who[which,(who$CountryID > 50 & who$CountryID <=100)]
> who4 = subset(who,who$CountryID > 50 & who$CountryID <=100)sample抽样,机器学习中抽取两份样本,一份用来建模,一份用来验证模型的有效性
> ?sample
## 例子,第一个参数为是选择那个向量,第二个是要抽取的个数,replace 表示是否放回式的抽样.
> x = 1:100
> sample(x,30,replace = T)
[1] 39 23 11 26 50 86 86 71 26 6 10 93 81 73 74 87 98
[18] 6 17 87 10 69 51 24 22 70 33 68 97 82
> sort(sample(x,30,replace = T))
[1] 8 19 23 23 28 31 32 40 40 42 50 50 50 51 52 55 58
[18] 60 63 70 73 77 78 83 83 84 85 89 93 96sample对数据框进行抽样,取子集
> who[sample(who$CountryID,30,replace = F),]删除固定行的数据
## 注意逗号的位置
> mtcars[-1:-5,]
## 清空这一行的数据
> mtcars$mpg = NULL 如果遇到几个数据表进行汇总,这里要用到数据框的合并,可以使用cbind和rbind函数,cbind添加一列,rbind添加一行.
cbind合并列
## USArrests是一个数据集,state.division是一个因子
> cbind(USArrests,state.division)rbind合并行,这个比较麻烦,需要所有的列有源数据集有相同的列名
## 取出前20行和尾20行合并
> data1 = head(USArrests,20)
> data2 = head(USArrests,20)
> b = rbind(data1,data2)cbind和rbind也可以用于矩阵
回顾rownames可以取出行名
判断向量和数据框中哪些是重复值
> duplicated(who)用unique(data4)可以一步取出重复项
36-数据转换(三)
R中行列的调换,excel中可以复制后选择性粘贴.R中可以用t()函数实现转换
> sractm = t(mtcars)单独一行的反转,生物序列中很常见,主要是反向互补,可以使用rev函,reverse的意思
> letters
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l"
[13] "m" "n" "o" "p" "q" "r" "s" "t" "u" "v" "w" "x"
[25] "y" "z"
> rev(letters)
[1] "z" "y" "x" "w" "v" "u" "t" "s" "r" "q" "p" "o"
[13] "n" "m" "l" "k" "j" "i" "h" "g" "f" "e" "d" "c"
[25] "b" "a"数据框中的数据反转,思路就是,提取行名,反转,以反转后的行名为索引
> rowname(women)
> rev(rowname(women))
> women[rev(rowname(women))]如何修改数据框中的值,可以使用transform()
## 比如
> transform(women,height=height*2.54)排序
sort可以对向量进行排序,可以排序数字,字母,
sort中也可以设置参数decreasing = T进行从大小排序
> sort(rivers,decreasing = T)order排序返回的是排序后的索引值,在数据框中是比较常用的.返回索引值后可以拿来数据框的排序
## 如果换成sort就不行了
> mtcars[order(mtcars$mpg),]
## "-"反向排序,也可以加参数decreasing = T
> mtcars[order(-mtcars$mpg),]
> mtcars[order(mtcars$mpg,decreasing = T),]其次还有rank 函数,
37-数据转换(四)
如何对数据框进行数学计算
统计
worldphones = as.data.frame(WorldPhones) ## 转换成数据框
rs = rowSums(worldphones) ## 对行进行求和
cm = colMeans(worldphones) ## 对列求平均
total = cbind(worldphones,Total=rs) ## 添加一列
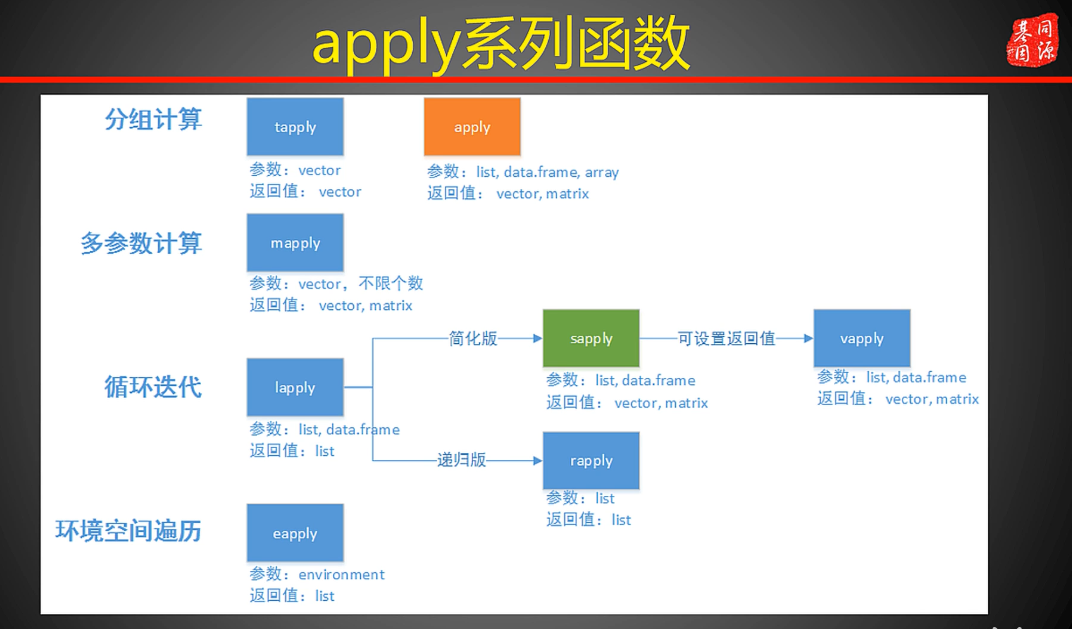
rbind(total,cm) ## 添加一行apply函数,使用与数据框和矩阵,可以有多个功能参数
主要四两个参数,margin,fun;margin = 1表示对行进行求和,2表示对列进行求和.fun表示功能,要进行的操作
> ?apply
## 对行求和
> apply(WorldPhones,MARGIN = 1,FUN = sum)
## 对列求平均值
> apply(WorldPhones,MARGIN = 2,FUN = mean)lapply 表示list apply ,适用于list列表
> lapply(state.center, length)
$x
[1] 50
$y
[1] 50sapply
> sapply(state.center, length)
x y
50 50 tapply 用于处理因子数据,根据因子分组,然后根据因子分组进行处理
第一个参数问数据集,第三个参数是要使用的函数
没咋懂!!!
> tapply(state.name,state.division,FUN=length)
New England Middle Atlantic
6 3
South Atlantic East South Central
8 4
West South Central East North Central
4 5
West North Central Mountain
7 8
Pacific
5 R中数据的中心化与标准化处理
数据的中心化,是指数据集中的各项数据减去数据集的均值
数据的标准化,是指在中心化后在除以数据集的标准差,即数据集中的各项数据减去数据集的均值再除以数据集的标准差.
R中实现中心化和标准化可以用scale函数,有两个参数,center和scale
比如state.x77这个数据集
> x = scale(state.x77,center = T,scale = T)
> heatmap(x)38-数据格式的转换(reshape2包)
大概的过程相当于钢铁的制造过程,先把铁融化,然后在做成想要的形状.在数据的过程中,称为柔数据,很像是excel中的数据透视表.
## 这里是一组空气质量的数据
> names(airquality) = tolower(names(airquality)) ## 把首字母小写
> melt(airquality) ## 融合数据
> aql = melt(airquality) ## 融合后数据变为三列
> aql = melt(airquality,id.vars = c("month","day")) ## 将月份和日期作为id变量.
> aqw = dcast(aql,month+day ~variable) ## 重铸数据,与variable相关联
> aqw = dcast(aql,month+day ~variable,fun.aggregate = mean,na.rm=TRUE)没怎么听懂. 可以在右下的框框中找到reshape2的帮助包,找到acast和dcast把其中的案例都运行一边,
~ 表示有关联有关系
39-数据格式的转换(tidyr包)
简洁数据中
- 每一列代表一个变量
- 每一行代表一个观测
- 每一个观测的值在表中的一个单元格中
tidyr包中有四个重要的函数
- gather 主要是将宽数据转换成长数据,类似于reshape2包中的melt函数
- spread 将长数据转换成宽数据,类似于reshape中的cast函数
- unite 是将多列合并为一列
- separate 是将一列分成多列
mtcars数据集为例,就是一个标准的tidydata数据集
> tdata = mtcars[1:10,1:3]
> tdata
mpg cyl disp
Mazda RX4 21.0 6 160.0
Mazda RX4 Wag 21.0 6 160.0
Datsun 710 22.8 4 108.0
Hornet 4 Drive 21.4 6 258.0
Hornet Sportabout 18.7 8 360.0
Valiant 18.1 6 225.0
Duster 360 14.3 8 360.0
Merc 240D 24.4 4 146.7
Merc 230 22.8 4 140.8
Merc 280 19.2 6 167.6
## 以第一列的数据添加到数据集中
> tdata = data.frame(names=rownames(tdata),tdata)
> tdata
names mpg cyl disp
Mazda RX4 Mazda RX4 21.0 6 160.0
Mazda RX4 Wag Mazda RX4 Wag 21.0 6 160.0
Datsun 710 Datsun 710 22.8 4 108.0
Hornet 4 Drive Hornet 4 Drive 21.4 6 258.0
Hornet Sportabout Hornet Sportabout 18.7 8 360.0
Valiant Valiant 18.1 6 225.0
Duster 360 Duster 360 14.3 8 360.0
Merc 240D Merc 240D 24.4 4 146.7
Merc 230 Merc 230 22.8 4 140.8
Merc 280 Merc 280 19.2 6 167.6gather函数,可以调整行列
## 对dyl,disp,mpg进行处理,如下
> gather(tdata,key = "Key",value = "Value",cyl,disp,mpg)
names Key Value
1 Mazda RX4 cyl 6.0
2 Mazda RX4 Wag cyl 6.0
3 Datsun 710 cyl 4.0
4 Hornet 4 Drive cyl 6.0
5 Hornet Sportabout cyl 8.0
6 Valiant cyl 6.0
7 Duster 360 cyl 8.0
8 Merc 240D cyl 4.0
9 Merc 230 cyl 4.0
10 Merc 280 cyl 6.0
11 Mazda RX4 disp 160.0
12 Mazda RX4 Wag disp 160.0
13 Datsun 710 disp 108.0
14 Hornet 4 Drive disp 258.0
15 Hornet Sportabout disp 360.0
16 Valiant disp 225.0
17 Duster 360 disp 360.0
18 Merc 240D disp 146.7
19 Merc 230 disp 140.8
20 Merc 280 disp 167.6
21 Mazda RX4 mpg 21.0
22 Mazda RX4 Wag mpg 21.0
23 Datsun 710 mpg 22.8
24 Hornet 4 Drive mpg 21.4
25 Hornet Sportabout mpg 18.7
26 Valiant mpg 18.1
27 Duster 360 mpg 14.3
28 Merc 240D mpg 24.4
29 Merc 230 mpg 22.8
30 Merc 280 mpg 19.2
## 可用"-"号,将disp单独放入一列中,
> gdata = gather(tdata,key = "Key",value = "Value",cyl,-disp,mpg)
> gdata
names disp Key Value
1 Mazda RX4 160.0 cyl 6.0
2 Mazda RX4 Wag 160.0 cyl 6.0
3 Datsun 710 108.0 cyl 4.0
4 Hornet 4 Drive 258.0 cyl 6.0
5 Hornet Sportabout 360.0 cyl 8.0
6 Valiant 225.0 cyl 6.0
7 Duster 360 360.0 cyl 8.0
8 Merc 240D 146.7 cyl 4.0
9 Merc 230 140.8 cyl 4.0
10 Merc 280 167.6 cyl 6.0
11 Mazda RX4 160.0 mpg 21.0
12 Mazda RX4 Wag 160.0 mpg 21.0
13 Datsun 710 108.0 mpg 22.8
14 Hornet 4 Drive 258.0 mpg 21.4
15 Hornet Sportabout 360.0 mpg 18.7
16 Valiant 225.0 mpg 18.1
17 Duster 360 360.0 mpg 14.3
18 Merc 240D 146.7 mpg 24.4
19 Merc 230 140.8 mpg 22.8
20 Merc 280 167.6 mpg 19.2
## 也可以用列号
gather(tdata,key = "Key",value = "Value",2:4)spread 函数,基本和gather相反
> spdata = spread(gdata,key = "Key",value = "Value")
> spdata
names cyl disp mpg
1 Datsun 710 4 108.0 22.8
2 Duster 360 8 360.0 14.3
3 Hornet 4 Drive 6 258.0 21.4
4 Hornet Sportabout 8 360.0 18.7
5 Mazda RX4 6 160.0 21.0
6 Mazda RX4 Wag 6 160.0 21.0
7 Merc 230 4 140.8 22.8
8 Merc 240D 4 146.7 24.4
9 Merc 280 6 167.6 19.2
10 Valiant 6 225.0 18.1spread默认识别”.”分割符,sep可以指定分隔符如:
> df = data.frame(x = c(NA,"a.b","a.c","b.c")
> df
x
1 <NA>
2 a.b
3 a.c
4 b.c
> separate(df,col = x,into = c("A","B"),sep = "-")
A B
1 <NA> <NA>
2 a b
3 a c
4 b cunite是一个相反的操作
> unite(x,col = "CD",A,B,sep = "-")
CD
1 NA-NA
2 a-b
3 a-c
4 b-c40-数据格式的转换(dplyr包)
这是一个非常强大的包
> ls("package:dplyr") ## 可以列出包的所有的函数dplyr::filer功能,根据给定条件,对数据进行过滤,例如
## dplyr::是调用的这个包中的函数,因为函数太多所以可以防止出现奇异
> dplyr::filter(iris,Sepal.Length>7) ## 过滤出花萼长度大于7的
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.1 3.0 5.9 2.1 virginica
2 7.6 3.0 6.6 2.1 virginica
3 7.3 2.9 6.3 1.8 virginica
4 7.2 3.6 6.1 2.5 virginica
5 7.7 3.8 6.7 2.2 virginica
6 7.7 2.6 6.9 2.3 virginica
7 7.7 2.8 6.7 2.0 virginica
8 7.2 3.2 6.0 1.8 virginica
9 7.2 3.0 5.8 1.6 virginica
10 7.4 2.8 6.1 1.9 virginica
11 7.9 3.8 6.4 2.0 virginica
12 7.7 3.0 6.1 2.3 virginicadplyr::distinct用于去除重复行,相当于unic
> dplyr::distinct(rbind(iris[1:10,],iris[1:15,]))
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
11 5.4 3.7 1.5 0.2 setosa
12 4.8 3.4 1.6 0.2 setosa
13 4.8 3.0 1.4 0.1 setosa
14 4.3 3.0 1.1 0.1 setosa
15 5.8 4.0 1.2 0.2 setosadplyr::slice()用于切片
> dplyr::slice(iris,10:15)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 4.9 3.1 1.5 0.1 setosa
2 5.4 3.7 1.5 0.2 setosa
3 4.8 3.4 1.6 0.2 setosa
4 4.8 3.0 1.4 0.1 setosa
5 4.3 3.0 1.1 0.1 setosa
6 5.8 4.0 1.2 0.2 setosadplyr::filter(iris,Sepal.Length>7)过滤出花萼长度大于7的花dplyr::slice(iris,10:15)表示切出10:15的行dplyr::sample_n(iris,10)表示随机抽取10行dplyr::sample_frac(iris,0.1)按比例抽取10分之一的数据dplyr::arrange(iris,Sepal.Length)表示安装花萼长度进行排序dplyr::arrange(iris,desc(Sepal.Length))表示反向进行排序
dplyr中取子集的功能
介绍中?select中有大量的示例
dplyr的统计函数
可以使用summarise进行统计
summarise(iris,avg=mean(Sepal.Length))可以计算花萼的平均长度summarise(iris,sum=sum(Sepal.Length))可以计算花萼的总长度
链式操作符%>%
将一个函数的输出传递给下一个函数,用作下一个函数的输入,类似于linux中的管道,Rstudio中可以使用ctrl+shift+M调用
iris 通过管道进行分组,再通过管道计算平均值,再通过管道进行排序
> iris %>% group_by(Species) %>% summarise(avg=mean(Sepal.Width)) %>% arrange(avg)
`summarise()` ungrouping output (override with `.groups` argument)
# A tibble: 3 x 2
Species avg
<fct> <dbl>
1 versicolor 2.77
2 virginica 2.97
3 setosa 3.43mutate可以添加新的变量
dplyr中双表格的操控
整合方式包括左连接,有链接,内连接,全连接,半连接,反链接等.内连接是取交集,全连接是取并集.
## 建立两个数据框
> a = data.frame(x1=c("A","B","C"),x2=c(1,2,3))
> b = data.frame(x1=c("A","B","D"),x3=c(T,F,T))
## 左连接,就是以左边的表为基础进行合并
> dplyr::left_join(a,b,by="x1")
x1 x2 x3
1 A 1 TRUE
2 B 2 FALSE
3 C 3 NA
## 右连接,就是以右边的表为基础进行合并
> dplyr::right_join(a,b,by="x1")
x1 x2 x3
1 A 1 TRUE
2 B 2 FALSE
3 D NA TRUE
## 全连接取并集
> dplyr::full_join(a,b,by="x1")
x1 x2 x3
1 A 1 TRUE
2 B 2 FALSE
3 C 3 NA
4 D NA TRUE
## 半链接根据右侧表的内容于对左侧表进行过滤,不要交集,对a表进行操作.
> dplyr::semi_join(a,b,by="x1")
x1 x2
1 A 1
2 B 2
## 反链接也是根据右侧表进行操作,是将左侧表的补集取出来.对a表进行操作.
> dplyr::anti_join(a,b,by="x1")
x1 x2
1 C 341-R函数
类似于linux中是命令

lm 是一个回归分析
老师强调的是多用.
42-选项参数
程序,选项,参数
选项参数:
- 输入控制部分
- 输出控制部分
- 调节部分
在linux中数据几个参数就被称作几元函数,R中也是一样的
视频
还是要不停的操作
43-数学统计函数
概率论是统计学的基础,R有许多处理概率的函数.可能涉及到,样本空间,对立与互斥,随机事件与必然事件,概率密度,概率分布等.这个要你有统计学相关的书籍
- d 概率密度函数
- p 分布函数
- q 分布函数的反函数
- r 产生相同分布的随机函数
正太分布相关的函数
## 分别为正太概率密度函数,正太分布函数,正太分位数函数,正太分布的随机数函数
?Normal
dnorm(x, mean = 0, sd = 1, log = FALSE)
pnorm(q, mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE)
qnorm(p, mean = 0, sd = 1, lower.tail = TRUE, log.p = FALSE)
rnorm(n, mean = 0, sd = 1)比如随机生成100个随机的正太分布的数字
> rnorm(n = 100,mean = 15,sd = 2)
[1] 18.82627 14.48052 15.64733 17.10765 16.69834
[6] 17.18229 15.82709 14.38638 17.03382 15.75992
[11] 15.62620 15.91558 16.44487 12.72194 15.26981
[16] 15.41339 17.40237 16.06431 14.18183 13.73592
[21] 14.57075 14.18284 15.91646 15.79732 12.86899
[26] 10.33624 11.68006 17.04716 11.75353 14.56665
[31] 19.45208 10.68233 13.43531 13.47316 14.27902
[36] 19.29866 12.14214 15.09897 12.73730 14.76324
[41] 13.53597 19.82190 18.34059 14.48723 16.30598
[46] 12.61513 15.49195 14.33117 15.56077 15.10224
[51] 18.87988 10.82265 17.50272 16.03550 13.69167
[56] 15.53061 14.92809 13.31095 16.12193 13.37350
[61] 14.97857 17.93824 15.81937 15.14789 15.02264
[66] 15.35681 15.06818 16.20024 15.49239 13.87530
[71] 15.07941 11.02497 15.94322 15.67173 12.82916
[76] 14.49088 15.23593 14.89429 15.39066 17.03379
[81] 15.07567 13.72972 15.06769 16.03017 18.25667
[86] 11.01588 12.57675 17.13522 16.01980 10.52023
[91] 19.66291 13.17814 17.31925 14.03456 16.18037
[96] 15.59317 12.31323 16.43977 16.09725 14.29555
> round(rnorm(n = 100,mean = 15,sd = 2)) ## 可用于取整数,每次运行都是不同正太分布的数字与离散分布相关的函数
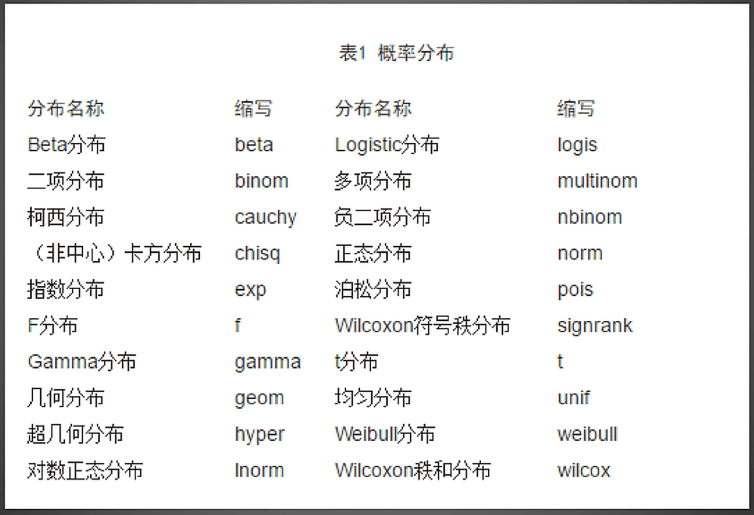
比如几种分布
## 集合分布
> ?Geometric
## 超几何分布
> ?Hypergeometric这些函数的作用,,,
- 可以生成这种函数的随机数,并绘制出对应的分布曲线来查看,比如
> x = rnorm(n=100,mean = 15,sd = 2) > qqnorm(x)
随机数的生成
> runif(10)*10
## 生成50个最小为1最大为100的随机数
> runif(50,min=1,max=100)随机种子,要求复现,这时就要用到set.seed()如:
## 每次这样运行都可以得到同样的随机数
> set.seed(666)
> runif(10)
[1] 0.77436849 0.19722419 0.97801384 0.20132735
[5] 0.36124443 0.74261194 0.97872844 0.49811371
[9] 0.01331584 0.2599461344-描述性统计函数
summary函数
回归分析中大量的用到这个函数
## 提供了最小,四分位数,中位数,平均值,,最小值,,
> myvare = mtcars[c("mpg","hp","wt","am")]
> summary(myvare)
mpg hp wt am
Min. :10.40 Min. : 52.0 Min. :1.513 Min. :0.0000
1st Qu.:15.43 1st Qu.: 96.5 1st Qu.:2.581 1st Qu.:0.0000
Median :19.20 Median :123.0 Median :3.325 Median :0.0000
Mean :20.09 Mean :146.7 Mean :3.217 Mean :0.4062
3rd Qu.:22.80 3rd Qu.:180.0 3rd Qu.:3.610 3rd Qu.:1.0000
Max. :33.90 Max. :335.0 Max. :5.424 Max. :1.0000fivenum()
与summary类似可以返回五个数,最小值,四分位数,中位数
> fivenum(myvare$hp)
[1] 52 96 123 180 335pastecs包
这个可以计算种类繁多的统计量
## 默认的 basic=T 计算基础统计值
> stat.desc(myvare)
mpg hp wt am
nbr.val 32.0000000 32.0000000 32.0000000 32.00000000
nbr.null 0.0000000 0.0000000 0.0000000 19.00000000
nbr.na 0.0000000 0.0000000 0.0000000 0.00000000
min 10.4000000 52.0000000 1.5130000 0.00000000
max 33.9000000 335.0000000 5.4240000 1.00000000
range 23.5000000 283.0000000 3.9110000 1.00000000
sum 642.9000000 4694.0000000 102.9520000 13.00000000
median 19.2000000 123.0000000 3.3250000 0.00000000
mean 20.0906250 146.6875000 3.2172500 0.40625000
SE.mean 1.0654240 12.1203173 0.1729685 0.08820997
CI.mean.0.95 2.1729465 24.7195501 0.3527715 0.17990541
var 36.3241028 4700.8669355 0.9573790 0.24899194
std.dev 6.0269481 68.5628685 0.9784574 0.49899092
coef.var 0.2999881 0.4674077 0.3041285 1.22828533
## 计算描述性统计
> stat.desc(myvare,basic = T)
mpg hp wt am
nbr.val 32.0000000 32.0000000 32.0000000 32.00000000
nbr.null 0.0000000 0.0000000 0.0000000 19.00000000
nbr.na 0.0000000 0.0000000 0.0000000 0.00000000
min 10.4000000 52.0000000 1.5130000 0.00000000
max 33.9000000 335.0000000 5.4240000 1.00000000
range 23.5000000 283.0000000 3.9110000 1.00000000
sum 642.9000000 4694.0000000 102.9520000 13.00000000
median 19.2000000 123.0000000 3.3250000 0.00000000
mean 20.0906250 146.6875000 3.2172500 0.40625000
SE.mean 1.0654240 12.1203173 0.1729685 0.08820997
CI.mean.0.95 2.1729465 24.7195501 0.3527715 0.17990541
var 36.3241028 4700.8669355 0.9573790 0.24899194
std.dev 6.0269481 68.5628685 0.9784574 0.49899092
coef.var 0.2999881 0.4674077 0.3041285 1.22828533
## norm 就会计算一些统计值,如正太分布统计量,偏度,峰度等
> stat.desc(myvare,norm = T)
mpg hp wt am
nbr.val 32.0000000 32.00000000 32.00000000 3.200000e+01
nbr.null 0.0000000 0.00000000 0.00000000 1.900000e+01
nbr.na 0.0000000 0.00000000 0.00000000 0.000000e+00
min 10.4000000 52.00000000 1.51300000 0.000000e+00
max 33.9000000 335.00000000 5.42400000 1.000000e+00
range 23.5000000 283.00000000 3.91100000 1.000000e+00
sum 642.9000000 4694.00000000 102.95200000 1.300000e+01
median 19.2000000 123.00000000 3.32500000 0.000000e+00
mean 20.0906250 146.68750000 3.21725000 4.062500e-01
SE.mean 1.0654240 12.12031731 0.17296847 8.820997e-02
CI.mean.0.95 2.1729465 24.71955013 0.35277153 1.799054e-01
var 36.3241028 4700.86693548 0.95737897 2.489919e-01
std.dev 6.0269481 68.56286849 0.97845744 4.989909e-01
coef.var 0.2999881 0.46740771 0.30412851 1.228285e+00
skewness 0.6106550 0.72602366 0.42314646 3.640159e-01
skew.2SE 0.7366922 0.87587259 0.51048252 4.391476e-01
kurtosis -0.3727660 -0.13555112 -0.02271075 -1.924741e+00
kurt.2SE -0.2302812 -0.08373853 -0.01402987 -1.189035e+00
normtest.W 0.9475647 0.93341934 0.94325772 6.250744e-01
normtest.p 0.1228814 0.04880824 0.09265499 7.836354e-08doBy包
可以一次返回多个计算统计量
## 右边的变量是分组型的分组变量,data接一个数据框,fun接一个函数,可以是自定义函数
> summaryBy(mpg+hp+wt ~ am,data = myvare,FUN = mean)
am mpg.mean hp.mean wt.mean
1 0 17.14737 160.2632 3.768895
2 1 24.39231 126.8462 2.41100045-频数统计函数
如果一个数据是因子,因子是直接可以进行分组的
> mt_cyl = as.factor(mtcars$cyl)
> mt_cyl
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8
[26] 4 4 4 8 6 8 4
Levels: 4 6 8
> split(mtcars,mt_cyl)
## 这样就可以根据气缸的个数对汽车进行分组如果不是一个明显的因子,可以用cut进行分割
## 10到50,以10为步长进行分组
> cut(mtcars$mpg,c(seq(10,50,10)))
[1] (20,30] (20,30] (20,30] (20,30] (10,20] (10,20]
[7] (10,20] (20,30] (20,30] (10,20] (10,20] (10,20]
[13] (10,20] (10,20] (10,20] (10,20] (10,20] (30,40]
[19] (30,40] (30,40] (20,30] (10,20] (10,20] (10,20]
[25] (10,20] (20,30] (20,30] (30,40] (10,20] (10,20]
[31] (10,20] (20,30]
Levels: (10,20] (20,30] (30,40] (40,50]
## 然后直接使用table进行统计
> table(cut(mtcars$mpg,c(seq(10,50,10))))
(10,20] (20,30] (30,40] (40,50]
18 10 4 0 prop.table计算频率函数
> prop.table(table(mtcars$cyl))
4 6 8
0.34375 0.21875 0.43750 vcd
如果是二维的数据框呢
- 如果是用table的话
## 安慰剂和治疗组的区分,这个在实验的时候很常用 > table(Arthritis$Treatment,Arthritis$Improved) None Some Marked Placebo 29 7 7 Treated 13 7 21
xtabs
这个函数是可以自定义公式
> xtabs(~ Treatment + Improved,data = Arthritis)
Improved
Treatment None Some Marked
Placebo 29 7 7
Treated 13 7 21二维列联表可以用margin.table
## 这里的1代表的是行
> x = xtabs(~ Treatment + Improved,data = Arthritis)
> margin.table(x)
[1] 84
> margin.table(x,1)
Treatment
Placebo Treated
43 41
## 频率占比统计
> prop.table(x,1)
Improved
Treatment None Some Marked
Placebo 0.6744186 0.1627907 0.1627907
Treated 0.3170732 0.1707317 0.5121951addmargins()可以直接将算出的和添加到表中,也可以设置1和2,只添加行或列.
> addmargins(x)
Improved
Treatment None Some Marked Sum
Placebo 29 7 7 43
Treated 13 7 21 41
Sum 42 14 28 84三维列联表的计算
> x = xtabs(~ Treatment + Improved + Sex,data = Arthritis)
> x
, , Sex = Female
Improved
Treatment None Some Marked
Placebo 19 7 6
Treated 6 5 16
, , Sex = Male
Improved
Treatment None Some Marked
Placebo 10 0 1
Treated 7 2 5
## 这样的表可能不是很好看,ftable()可以将表转换成评估式的列联表
> ftable(x)
Sex Female Male
Treatment Improved
Placebo None 19 10
Some 7 0
Marked 6 1
Treated None 6 7
Some 5 2
Marked 16 546-R中的独立性检验函数
独立检验是根据频数信息判断两类因子彼此相关或相互独立的假设检.所谓独立就是看看变量之间是否是独立的.
主要有三个检验方法
- 卡方检验
- Fisher检验
- Cochran-Mantel-Haenszel检验
假设检验
假设检验是梳理统计学中根据一定假设条件由样本推断总体的一种方法.
原假设–没有发生;
备择假设–发生了;
具体作法是:根据问题的需要对所研究的总体作某种假设,记作HO ;选取合适的统计量,这个统计量的选取要使得在假设H0成立时,其分布为已知;由实测的样本,计算出统计量的值,并根据预先给定的显著性水平进行检验,作出拒绝或接受假设HO的判断。
p-value probability的值
是一个通过计算得到的概率值,也就是原假设为真时,得到最大的或者超出所得到的检验统计量的概率.
一般将p值定位到0.05,当p < 0.05拒绝原假设,p > 0.05,不拒绝原假设.
简单的理解就是p值越小原假设越不靠谱,拒绝它,p值越大,说明原假设越靠谱,不拒绝它
p值越小相关性越大
以上次药物的有效性为例,进行卡方检验
> mytable = table(Arthritis$Treatment,Arthritis$Improved)
> chisq.test(mytable)
Pearson's Chi-squared test
data: mytable
X-squared = 13.055, df = 2, p-value = 0.001463
## p值为0.001463说明两个变量之间是有关系的,说明药物是有效果的
> mytable2 = table(Arthritis$Sex,Arthritis$Improved)
> chisq.test(mytable2)
Pearson's Chi-squared test
data: mytable2
X-squared = 4.8407, df = 2, p-value = 0.08889
## 这里检测的是性别与改善之间的关系fisher 精确检验
也是独立性检验,原理是行和列是独立
> fisher.test(mytable)
Fisher's Exact Test for Count Data
data: mytable
p-value = 0.001393
alternative hypothesis: two.sided
## 与卡方检验是一致的,计算的也是P值mantelhaen.test 检测
两个名义变量在第三个变量每一层中都是条件独立的,需要三个变量
> mytable3 = xtabs(~Treatment + Improved + Sex,data = Arthritis)
> mytable3
, , Sex = Female
Improved
Treatment None Some Marked
Placebo 19 7 6
Treated 6 5 16
, , Sex = Male
Improved
Treatment None Some Marked
Placebo 10 0 1
Treated 7 2 5
> mantelhaen.test(mytable3)
Cochran-Mantel-Haenszel test
data: mytable3
Cochran-Mantel-Haenszel M^2 = 14.632, df = 2, p-value = 0.0006647
## 这里的p值很小,因为列联表的结果是以性别来区分的,这里表示药物的治疗在性别的每一个水平上不独立.这里的独立性检验的顺序是很总要的
## 这里变量的顺序是很重要的
> mytable3 = xtabs(~Treatment + Sex + Improved ,data = Arthritis)
> mantelhaen.test(mytable3)
Mantel-Haenszel chi-squared test with continuity correction
data: mytable3
Mantel-Haenszel X-squared = 2.0863, df = 1, p-value = 0.1486
alternative hypothesis: true common odds ratio is not equal to 1
95 percent confidence interval:
0.8566711 8.0070521
sample estimates:
common odds ratio
2.619048 也由很多的包可以进行独立性检验
47-相关性分析函数
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。
简单来说就是变量之间是否有关系。
两个变量如果不独立就可以进行相关性检验,可能是正相关用”+”表示,也可能是负相关”-“,
相关性衡量指标,指标表示是都是同一个东西,只是表示的方法指标不同而已
- Pearson相关系数
- Spearman相关系数
- Kendall相关系数
- 偏相关系数
- 多分格相关系数
- 多系列相关系数
计算相关性系数都是使用同一个函数cor(),可以计算三种相关系数,pearson,kendall,spearman,默认是pearson
cor函数
## 这里计算一下谋杀率和什么有关
> ?cor
> state.x77
> cor(state.x77)
Population Income Illiteracy Life Exp Murder HS Grad Frost Area
Population 1.00000000 0.2082276 0.10762237 -0.06805195 0.3436428 -0.09848975 -0.3321525 0.02254384
Income 0.20822756 1.0000000 -0.43707519 0.34025534 -0.2300776 0.61993232 0.2262822 0.36331544
Illiteracy 0.10762237 -0.4370752 1.00000000 -0.58847793 0.7029752 -0.65718861 -0.6719470 0.07726113
Life Exp -0.06805195 0.3402553 -0.58847793 1.00000000 -0.7808458 0.58221620 0.2620680 -0.10733194
Murder 0.34364275 -0.2300776 0.70297520 -0.78084575 1.0000000 -0.48797102 -0.5388834 0.22839021
HS Grad -0.09848975 0.6199323 -0.65718861 0.58221620 -0.4879710 1.00000000 0.3667797 0.33354187
Frost -0.33215245 0.2262822 -0.67194697 0.26206801 -0.5388834 0.36677970 1.0000000 0.05922910
Area 0.02254384 0.3633154 0.07726113 -0.10733194 0.2283902 0.33354187 0.0592291 1.00000000这是一个对角矩阵对角线是自己与自己的相关性,都是1,最大相关系数.正的就是正相关,负的就是不相关,或反着来.
cov函数
可以用来计算协方差,基本与cor是一致的
> cov(state.x77)
Population Income Illiteracy Life Exp Murder HS Grad Frost Area
Population 19931683.7588 571229.7796 292.8679592 -4.078425e+02 5663.523714 -3551.509551 -77081.97265 8.587917e+06
Income 571229.7796 377573.3061 -163.7020408 2.806632e+02 -521.894286 3076.768980 7227.60408 1.904901e+07
Illiteracy 292.8680 -163.7020 0.3715306 -4.815122e-01 1.581776 -3.235469 -21.29000 4.018337e+03
Life Exp -407.8425 280.6632 -0.4815122 1.802020e+00 -3.869480 6.312685 18.28678 -1.229410e+04
Murder 5663.5237 -521.8943 1.5817755 -3.869480e+00 13.627465 -14.549616 -103.40600 7.194043e+04
HS Grad -3551.5096 3076.7690 -3.2354694 6.312685e+00 -14.549616 65.237894 153.99216 2.298732e+05
Frost -77081.9727 7227.6041 -21.2900000 1.828678e+01 -103.406000 153.992163 2702.00857 2.627039e+05
Area 8587916.9494 19049013.7510 4018.3371429 -1.229410e+04 71940.429959 229873.192816 262703.89306 7.280748e+09如果要精准的显示谋杀率和哪些指数有关
> colnames(state.x77)
[1] "Population" "Income" "Illiteracy" "Life Exp"
[5] "Murder" "HS Grad" "Frost" "Area"
> x = state.x77[,c(1,2,3,6)]
> y = state.x77[,c(4,5)]
> cor(x,y)
Life Exp Murder
Population -0.06805195 0.3436428
Income 0.34025534 -0.2300776
Illiteracy -0.58847793 0.7029752
HS Grad 0.58221620 -0.4879710cor函数只能计算三种算法,例如偏相关系数,多分隔系数,多系列系数,等.
偏相关系数
## 第一个参数是(前两个是要计算数值的下标,其余的是条件变量的下标),第二个参数是cov计算出来的协方差结果.
> ?pcor
> colnames(state.x77)
[1] "Population" "Income" "Illiteracy" "Life Exp"
[5] "Murder" "HS Grad" "Frost" "Area"
> pcor(c(1,5,2,3,6),cov(state.x77))
[1] 0.3462724
## 计算出偏相关系数
